TOC
Introduction
In this post, we’ll introduce the attention mechanisms and its applications in seq2seq model and transformer.
Attention Mechanisms
Attention is a generalized pooling methods with bias alignment over inputs. An input is called “query”, based on the “query” and the “memory”, the attention layer returns an output. To be more specific, assume the memory contains n key-value pairs $(k_1, v_1), (k_2, v_2)…(k_n, v_n)$ where $k_i \in R^{d_k}$ and $v_i \in R^{d_v}$. Given a query $q \in R^{d_q}$, the attention layer can give output $o \in R^{d_v}$ with the same shape as the value. The components of attention layer is shown in the image blow:
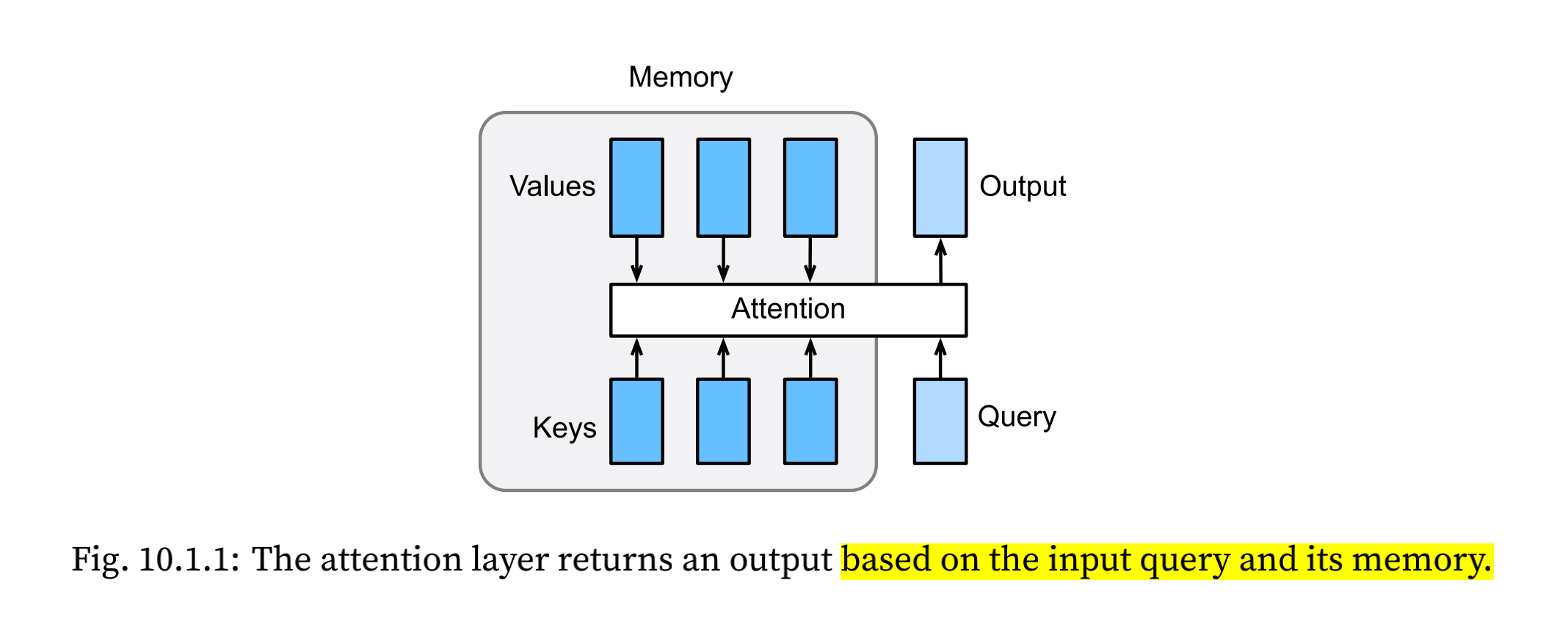
The full process of attention mechanisms are as follows:
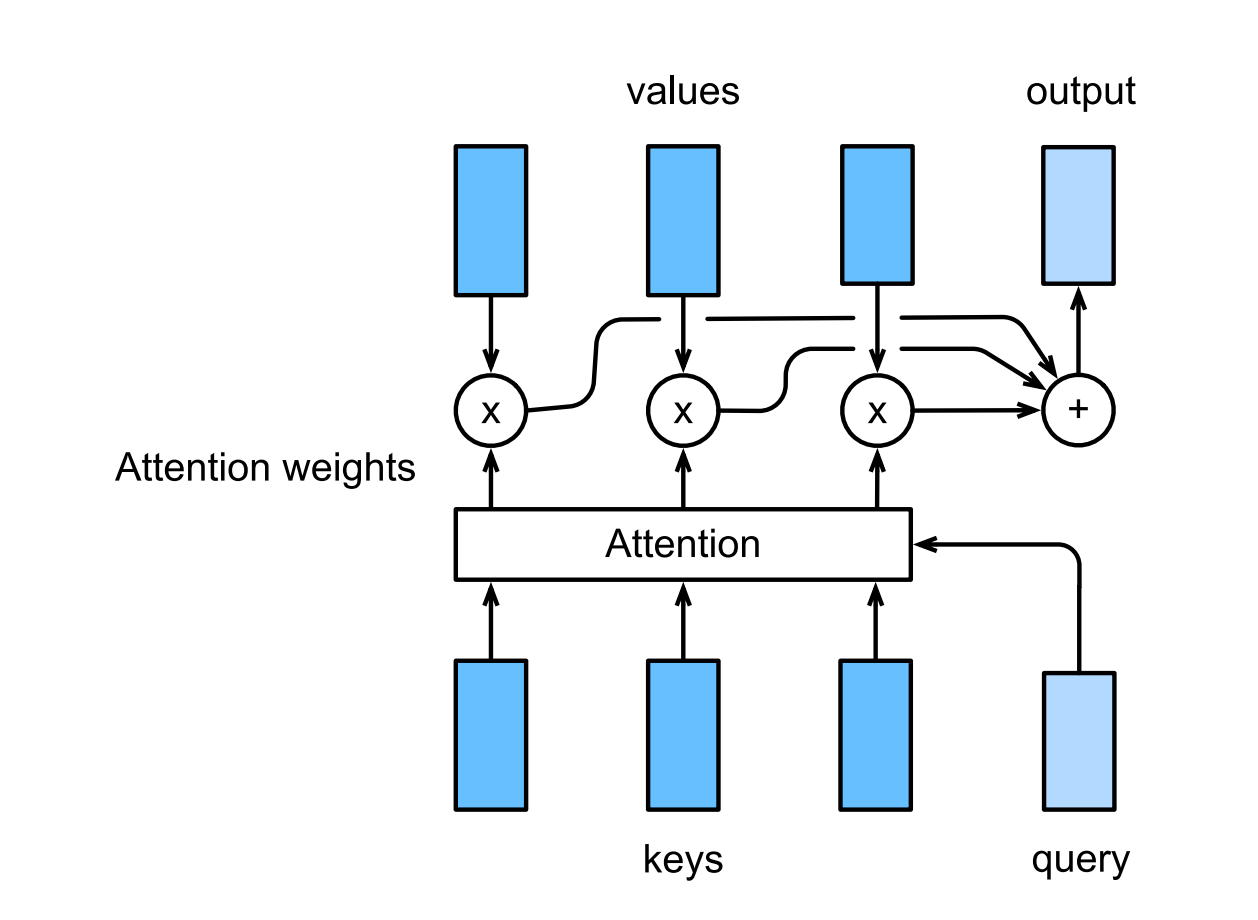
- First use a score function $\alpha$ to measure the similarity $a$ between $q$ and $k$. We can obtain $a_1, a_2 … a_n$ by: $a_i=\alpha(q, k_i)$
- Compute the attention weight using softmax: $b=softmax(a), where b_i=\frac{exp(a_i)}{\sum_j exp(a_i)} and b = [b_1, b_2, … b_n]^{T}$
- Finally, the output is the weighted sum of value: $o=\sum b_i*v_i$
The full process is illustrated in the follow figure.
Types of Attention Layer
Depending on the type of the score functions, the attention layers fall in two categories: dot production attention and multilayer attention.
For dot production attention, it assumes that the query and the key share the same dimension, namely $q, k \in R^{d}$. The score function is defined as:
$\alpha(q, k) = \frac{< q, k >}{\sqrt{d}}$
However, the query and key may not be of the same dimention. To address this issue, we restore to the multilayer attention, in which we project query and key into $R^{h} with learnable weights$. Assume the learnable weights are $W_k \in R^{h \times d_k}$, $W_q \in R^{h \times d_q}$ and $v^ \in R^{h}$. The score function can be defined as:
$\alpha(q, k) = v^{T}tanh(W_k k + W_q q)$
Sequence-to-sequence with Attention
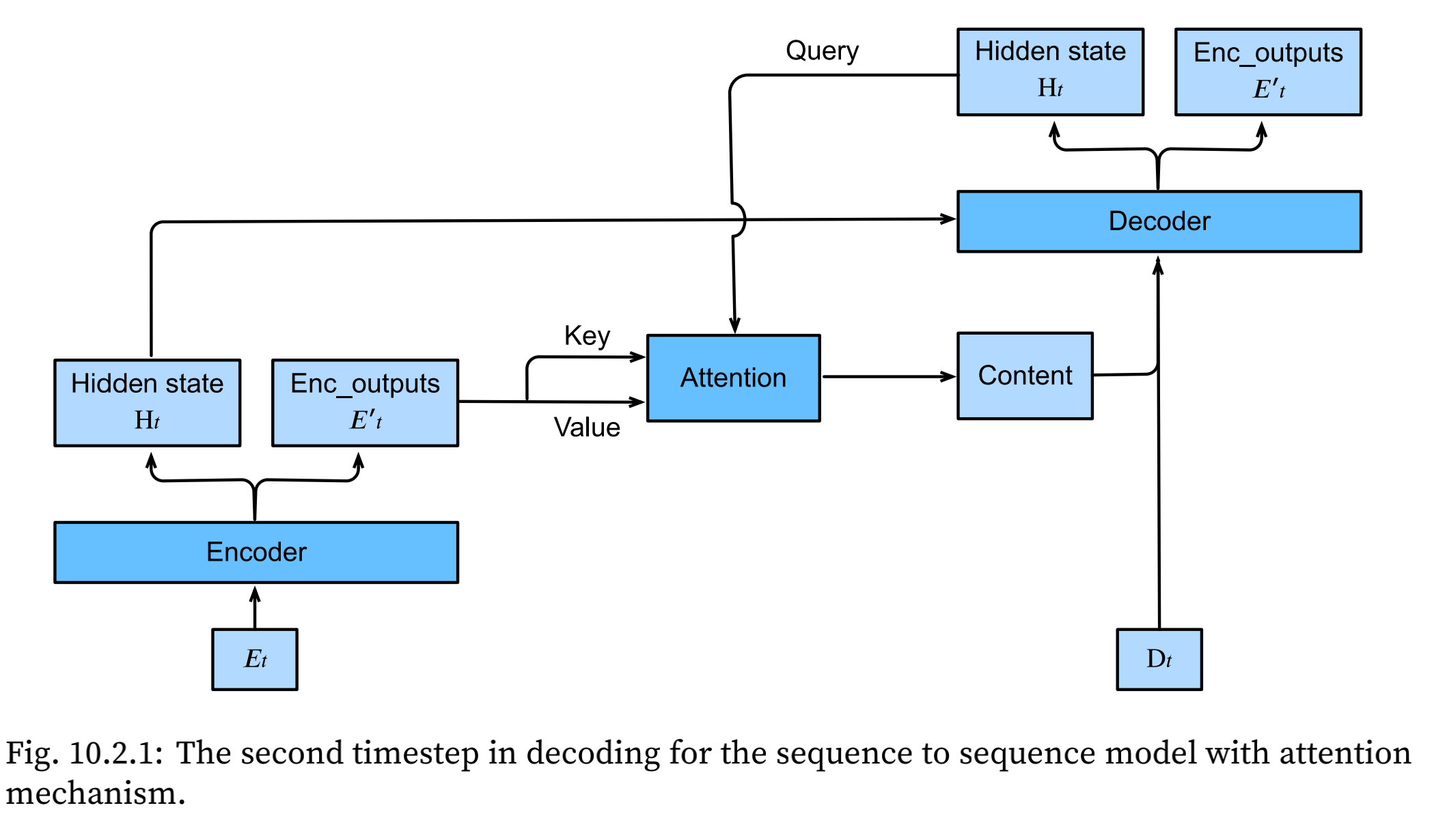
Three items are passed from encoder to decoder:
- Encoder output of all timestamps: they are used as the attention layer with the identical key and value.
- The hidden state of the encoder in the last timestamp: it is used as the initial decoder’s hidden state.
- The valid length of encoder: so the attention layer will not consider the padding tokens.
Transformer
CNN can easily parallelized at a lay but cannot capture variable-length sequential dependency. RNN can capture long-range, variable-length sequential dependency, but suffer from inability to parallelize in the sequence.
Transformer achieves the parallelization by capturing recurrence sequence with attention, at the same time encode each item’s position in the sequence. Similar to seq2seq, transformer utilize encoder-decoder architecture. However, transformer differs from the former by replacing the recurrent layers in seq2seq by multi-head attention layer, incorporating position-wise information through position encoding and apply layer normalization.
![]()