TOC
Introduction
This is the course notes of UC Berkeley CS285 deep reinforcement learning.
Intuition, Definition and Notation
Instead of learning from sparse rewards or specifying a manually reward function, the agent learns the optimal policy by learning, imitating the demonstrations of the experts.
Below shows the process:

Notations:
- $s_t$ state of the environment at time t
- $o_t$ observation of the agent at time t
- $a_t$ action of agent at time t
- ${\pi}_{\theta}(a_t | o_t)$: policy
- ${\pi}_{\theta}(a_t | s_t)$: policy(if fully observed)
- $p(s_{t+1}|a_t, s_t)$: transiton fuctions to $s_{t+1}$ given $a_t$ and $s_t$
Algorithms
| Type | Advantage | Disadvantage | Use When |
|---|---|---|---|
| Behavior Cloning | simple | no long-term planing error can add up | the application is simple |
| Direct Policy Learning | long-term planing | interavtive expert demonstrations needed | application is complex; interactive demonstration is available |
| Inverse Reinforcement Learning | long-term planing no need for interavtive demenstration | can be hard to train | interavtive demonstartion is no available; easier to learn reward function then expert policy |
Behavior Cloning
Definition: learning the expert’s policy with supervised learning.
Direct Policy Learning (by interactive demonstrator)
Definition: behavior cloning is a special of direct policy learning. First, supervised learning, then we roll out the game with the expert, and collect data. After that, we get more data demonstrated by the experts. Then go through the loop again.
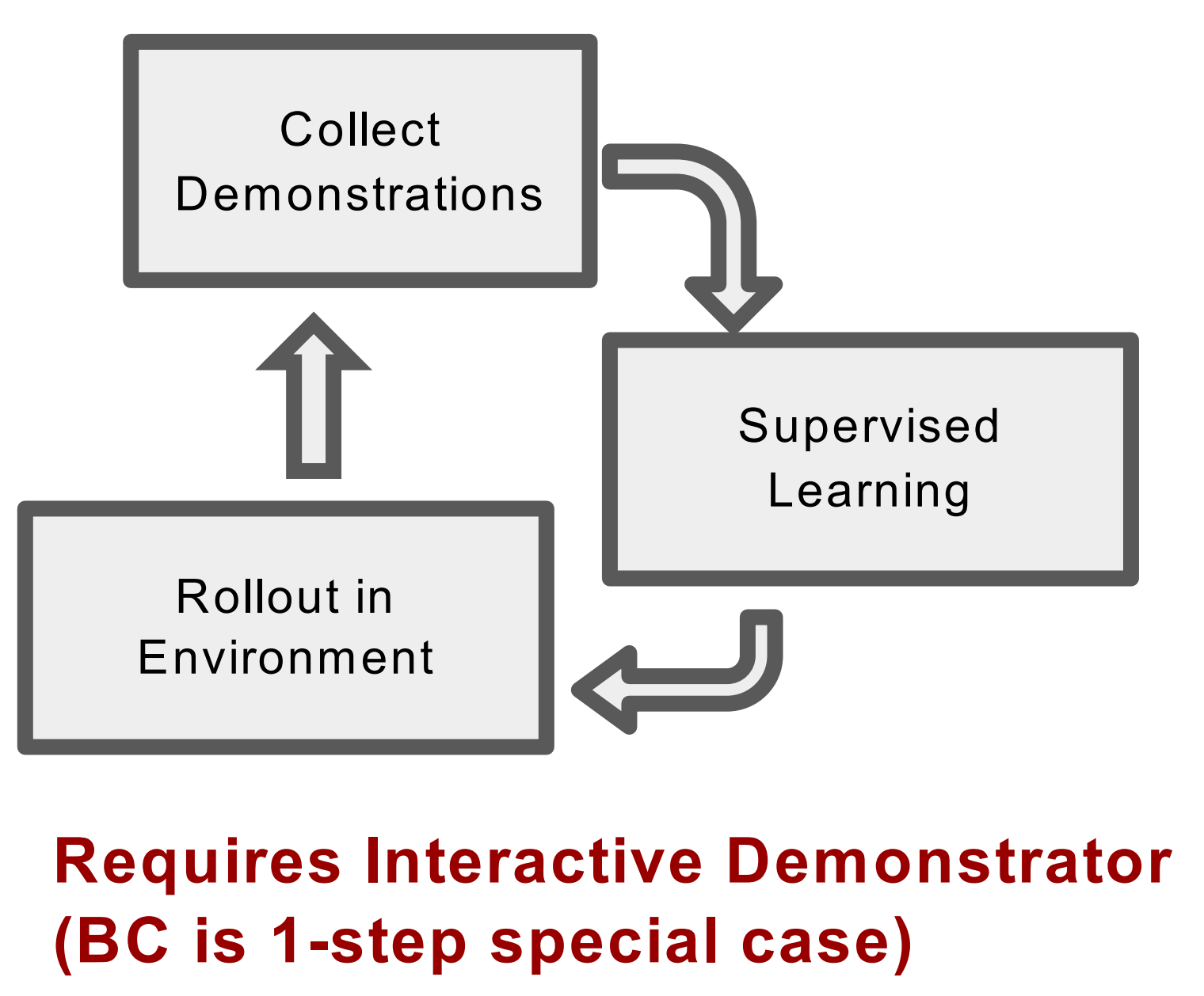
In the process of learning, the agent should ‘remembers’ all the mistakes that made. Two approches are used:
- Data aggregation (DAgger): agents are trained with all the history training data (The data will be relabeled by experts, then use these data to train the agent. refer to homework code)
- Policy aggregation: agents are only trained with data from the last iteration and then combined with policy from previous rounds with geometric blending.
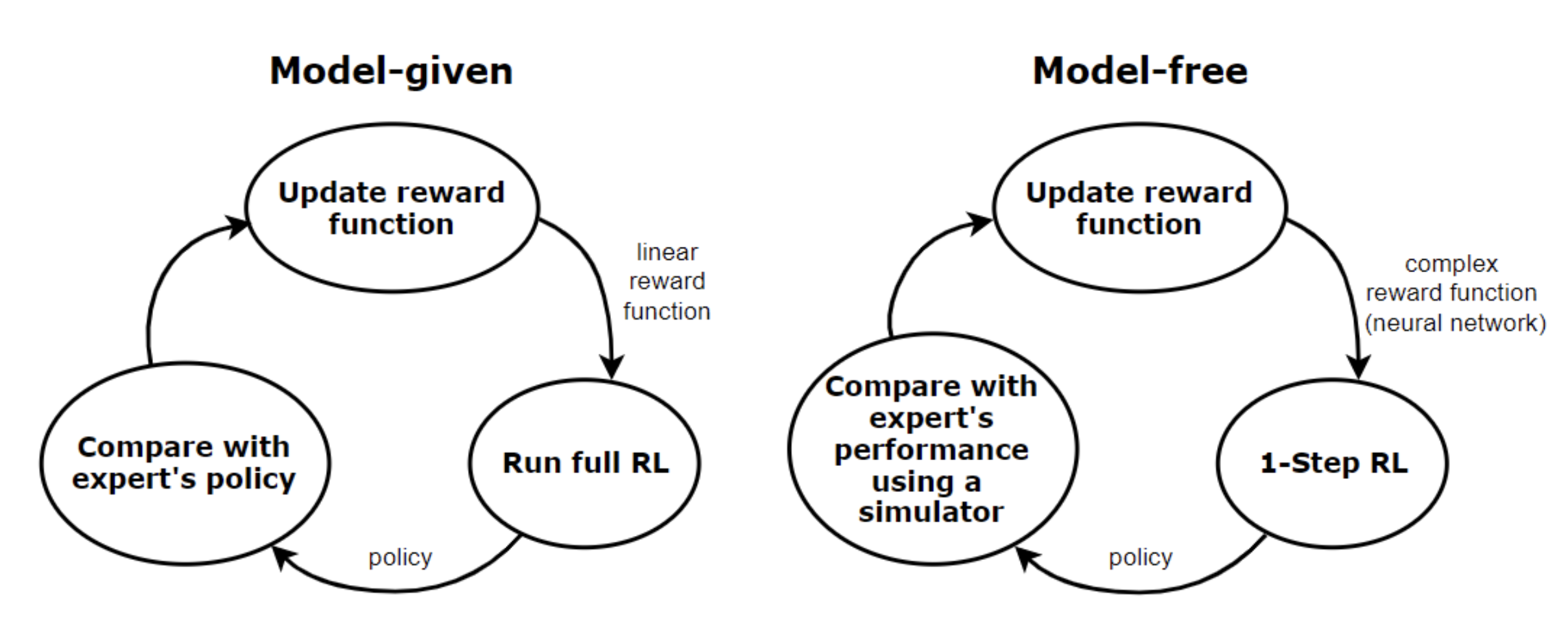
Inverse Reinforcement Learning
Definition: learn the reward function from the expert demonstrations, the train the agent with RL algorithms.
Procedures are as follows:

Two type of IRL: model-free and model-given
Applications
- Game AI
- Structured prediction
- etc..
Refer to imitation learning tutorial ICML 2018 video for more application practices