TOC
Introduction
This post illustrates how to train and deploy sklearn model with sklearn Pipeline and joblib
Training and Deployment with Pipeline and joblib in sklearn
Training model with pipeline:
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.naive_bayes import MultinomialNB
def process_text(text):
clean_words = jieba.lcut(str(text))
return clean_words
pipeline = Pipeline([
('bow',CountVectorizer(analyzer=process_text)), # converts strings to integer counts
('tfidf',TfidfTransformer()), # converts integer counts to weighted TF-IDF scores
('classifier',MultinomialNB()) # train on TF-IDF vectors with Naive Bayes classifier
])
pipeline.fit(...)
pipeline.predict(...)
Saving and Loading model with joblib:
joblib.dump(
value=pipeline,
filename=os.path.join(model_dir, model_file))
new_pipeline = joblib.load(
filename=file_name
)
Error & Solution
Error: module __main__ has no attribute
When deploying the model with joblib, I encountered this error:
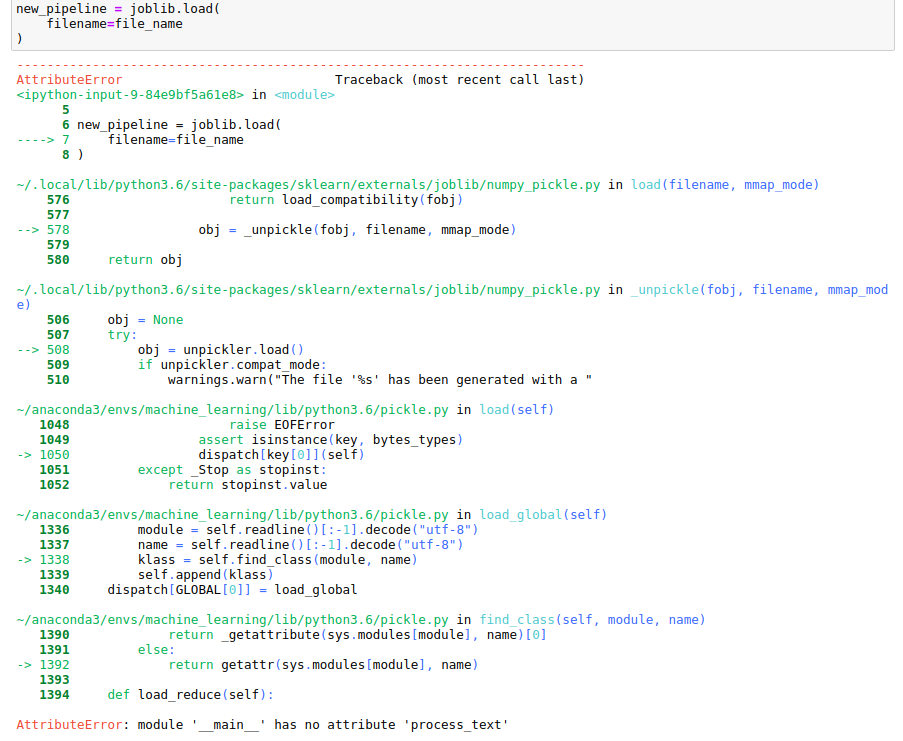
Refer to this stackoverflow answer. It’s because of the way I saved the model: Pickle does not dump the actual code classes and functions, only their names. It includes the name of the module each one was defined. If dumpping a class defined in a module you’re running as a script, it will dump the name main as the module name. In this case, function process_text will be saved as main.process_text.
I solved this errors with the following steps:
- put process_text, pipeline in a script named model.py
- import process_text, pipeline to another script, training the model there