TOC
Introduction
This is the course notes of deep learning specialization.
The sequence to sequence (seq2seq) model is based on encoder-decoder architecture to generate a sequence output from a sequence input. It’s mainly applied in machine translation, speech recognition and so on. When predicting, it utilizes beam search to improve the performance.
Encoder-decoder Architecture
Encoder-decoder is a neural network design pattern which consists of encoder and decoder. The encoder’s role is to encode the state into state. Then the decoder can utilize the state to generate the output. It can be used in machine translation, image captions and so on.

Seq2seq
Model Training
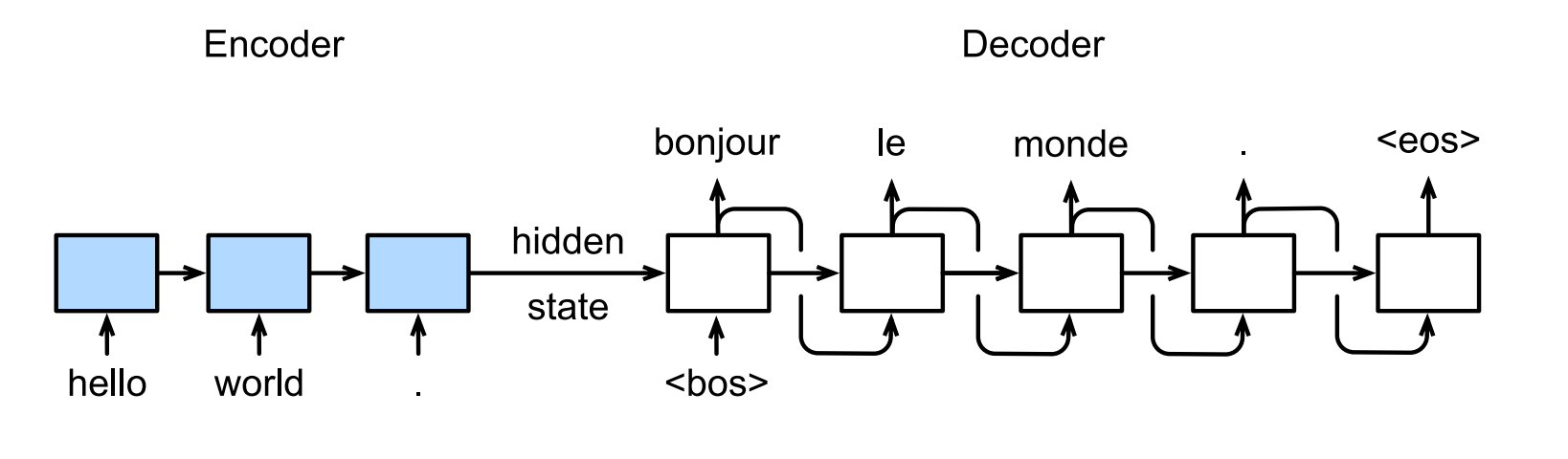
Below the training process for machine translation task:
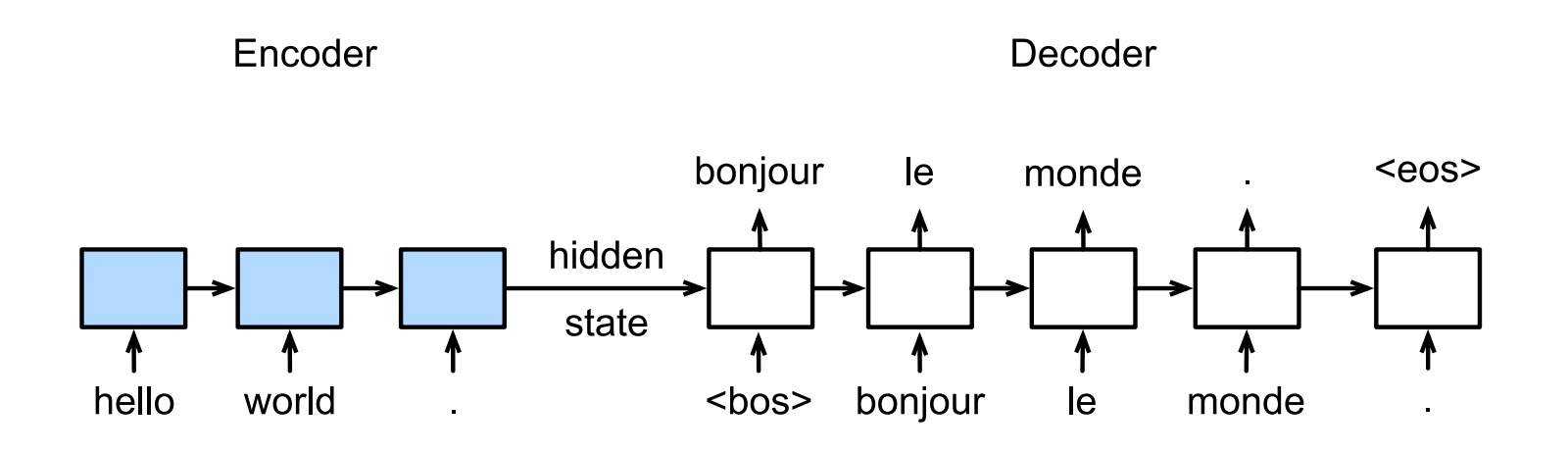
Prediction with Beam Search
The conditional probability of generating a sequence based on the input is: $\prod_{t=1}^{T_y}P(y^{<t>}|x,y^{<1>}…y^{<t-1>})$. In order to get a optimal sequence, we should apply search methods to maximize this probability.
For greedy search method, we search for the word that with the highest probability at this timestep. However, the optimal sequence can not be guaranteed. By examing all the possible sequences, the exhaustive search method can output the sequence with highest conditional probability. However, it can be slow. Beach search is an improved algorithms based on greedy search. At each timestep, we select k(beam size) word that with the highest probalities. We’ll take the sequence with the highest score which can be calculated by: $\frac{1}{T_y^{\alpha}}\sum_{t=1}^{T_y}P(y^{<t>}|x,y^{<1>}…y^{<t-1>})$. Here, $T_y$ is the length of final candidate sequence and the selection of $\alpha$ is general 0.75.