这是本系列课程的第四门课程,这门课程主要介绍卷积神经网络,其先介绍了卷积神经网络基础知识,后重点介绍了几个已有的成熟的神经网络模型,之后课程将注意力关注于物体检测,人脸识别和风格迁移等实际应用层面.
- 目标定位和目标检测
- 滑动窗口检测(Sliding windows detection)
- Bounding Box 预测
- 交并比(Intersection-over-union)
- 非极值压缩算法(non-max supression algorith)
- YOLO算法实例展示(拼装上述技术)
这个课程被分为三篇博客介绍, 此篇博客主要介绍目标检测问题. 这节前面先介绍了YOLO算法的细节技术, 然后拼装在一起实现了YOLO算法, 最后介绍了目标检测的另外一个思路:候选区域(region proposal)
课程中提到YOLO论文是一篇比较难的文献. 这个算法看了好久才看明白咋回事.
目标定位和目标检测
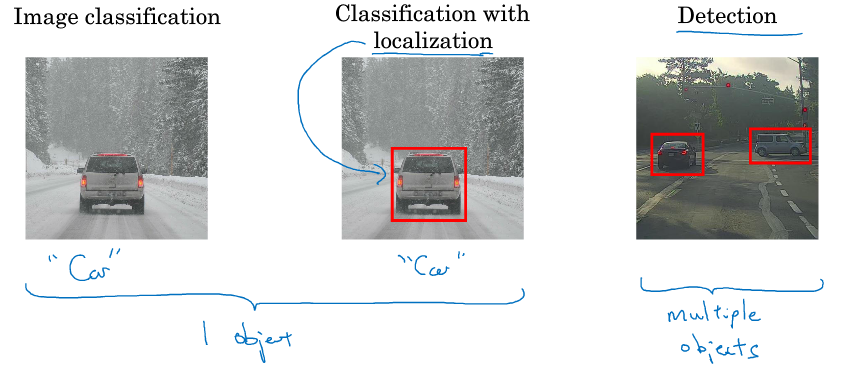
下图展示了三个问题:图像分类, 带有定位的图像分类和目标检测. 前两者图中有一个物体, 而后者图中有多个物体
Target label
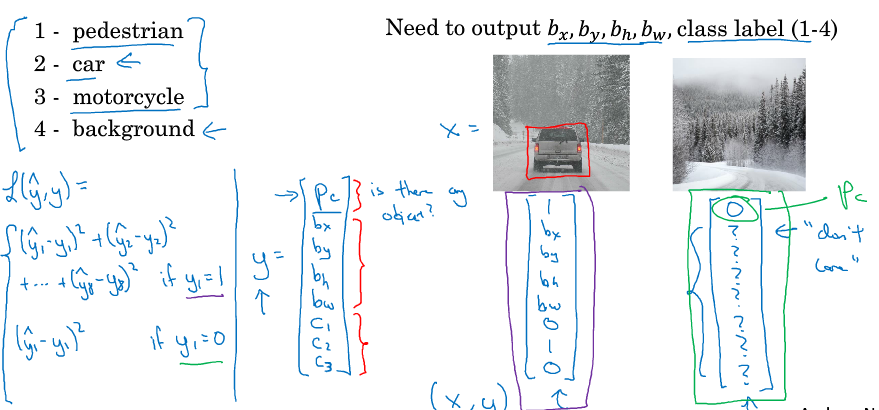
下图我们重新定义了图像检测的输出: 第一项 是否为物体, 后四项 物体的定位坐标, 最后三项 是个物体的概率
滑动窗口检测(Sliding windows detection)
滑动窗口检测如下图:

- 小窗口输入卷积神经网络, 判断是否有物体,
- 滑动窗口, 一个个输入检测
- 增大窗口检测
缺点: 计算量过大.
全连接层变为卷积层
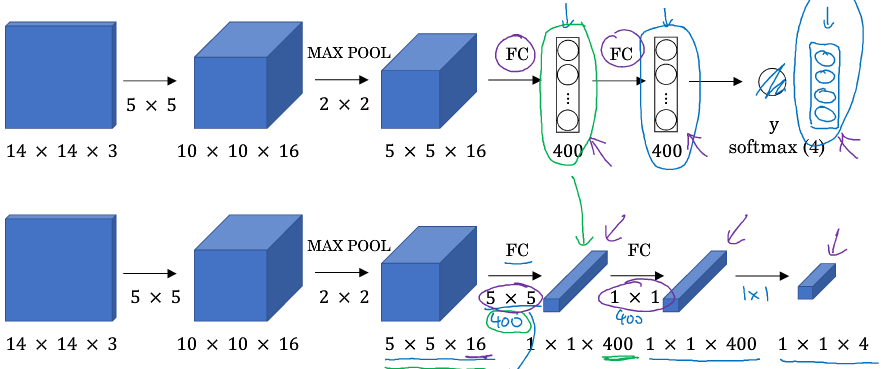
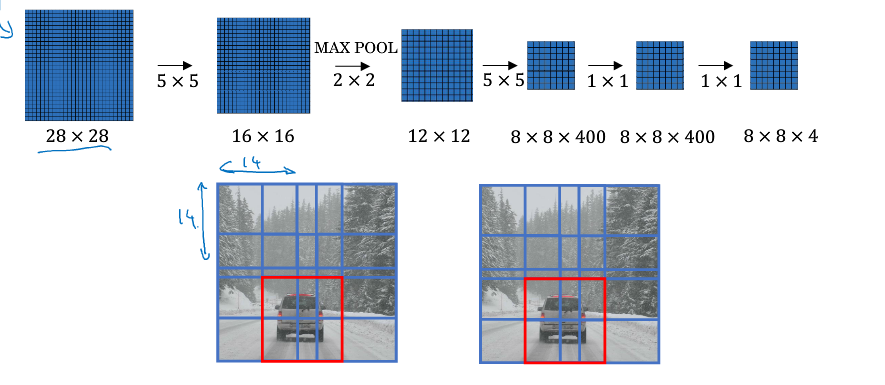
滑动窗口检测的卷积实现
滑动窗口检测中会有窗口共享参数, 为简化计算自然想到卷积实现, 如下图:
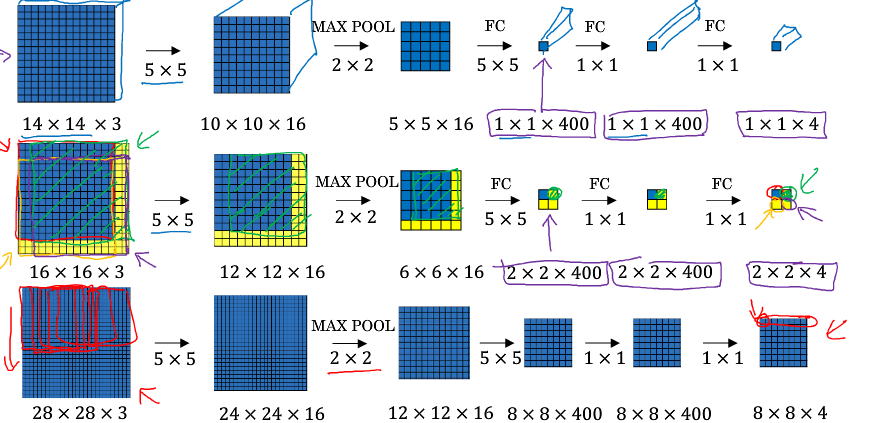
依照上面的办法, 不需进行窗口分割, 直接将图片输入卷积层, 便能得到结果, 大大提高整体计算效率
Bounding Box 预测
之前的卷积形式的滑动窗口算法无法输出精确的边界框, 下面展示YOLO算法:
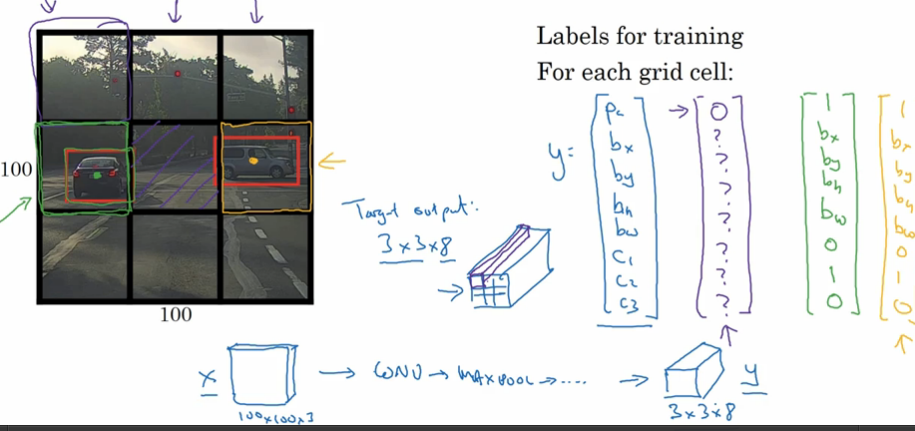
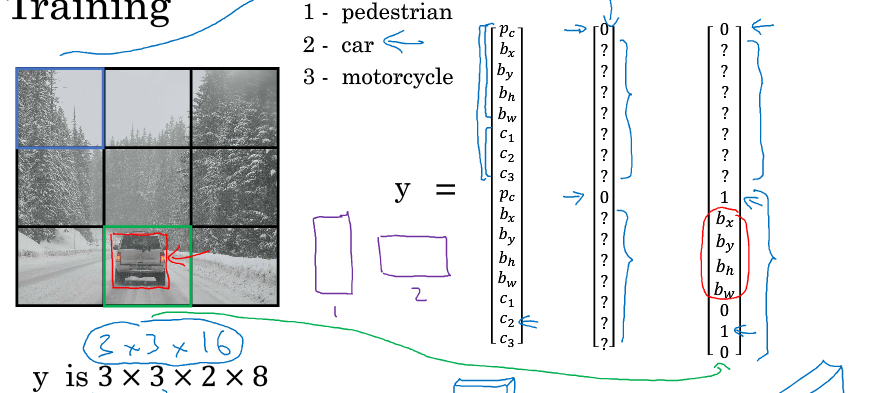
首先介绍YOLO算法中如何标注训练集:
- 将对象分配到对象中点所在网格中
- 其标签包含信息为以比例表示的中点坐标和长宽, 如下图:
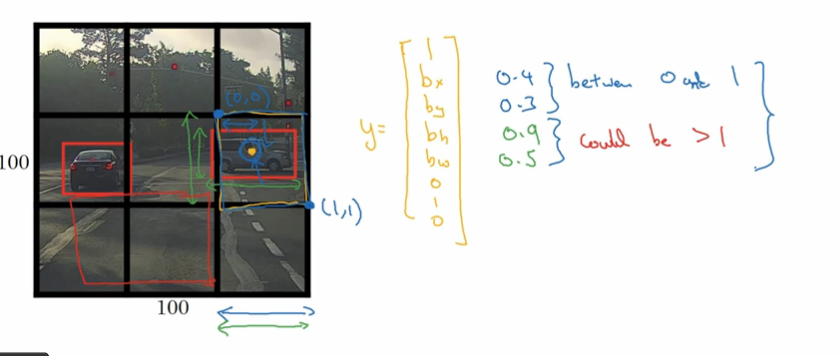
YOLO是一次单次卷积实现, 算法实现效率高, 运行速度快, 可以实时识别
交并比(Intersection-over-union)
交并比是用来评估目标定位的.
\(IoU = \frac{sizeof交}{size of 并}\)

非极值压缩算法(non-max supression algorith)
如下图, 在上面YOLO算法中, 可能出现多网格检测出一个物体

如下图,
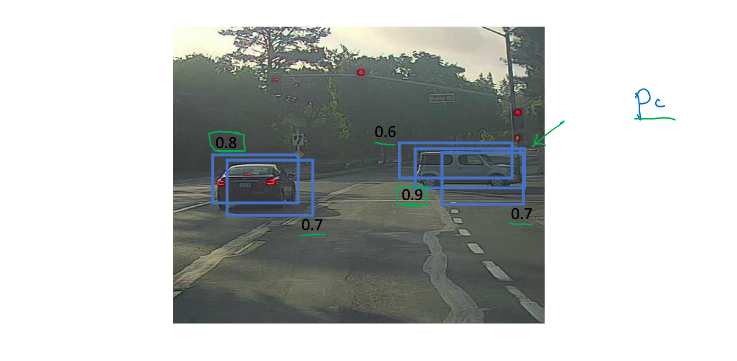
NMS算法思想如下(对于一类物体):
- 输出预测, 如上图
- 删除所有概率小于0.6的
- 当仍有边框未被处理时,进行下面算法(有多辆车时会多次进行):
- 选一个最大概率, 输出这个边框
- 删除所有和这个边框IoU”> 0.5 的边框(删除重复的), 返回上一步
YOLO算法实例展示(拼装上述技术)
输入和预测
- 图片输入为(100, 100, 3)划分为9*9的网格
- 包含三种物体: 行人, 车和摩托车,两个anchor: 行人和车, 则输出y维度为(3, 3, 2, 8)或(3, 3, 16)
输出非极大值抑制结果
输入图片如下:

进行预测, 得到(3, 3, 2, 8)输入, 将边框标在图上

第一步, 直接去除概率小于0.6的边框, 如下

第二步, 对行人, 汽车, 摩托车这三类边框分别进行非极值压缩算法, 最终输出如下:
