如果说第一门课程介绍了神经网络的基本框架,这门课开始在框架之上进行'修饰'(自己借用的词).主要涉及四部分知识:神经网络实际应用技巧,正则化,优化算法和超参数选择.
深度学习实际应用技巧
搭建深度学习应用
首先需要注意:应用深度学习的过程需要不断的迭代
实际数据集大小划分建议
| Train data | Dev(hold out) data | Test data | |
|---|---|---|---|
| Small data | 60% | 20% | 20% |
| Big Data | 98% | 1% | 1% |
对于来自不同分布的数据,要优先保持train data 和 Dev data来自同一分布
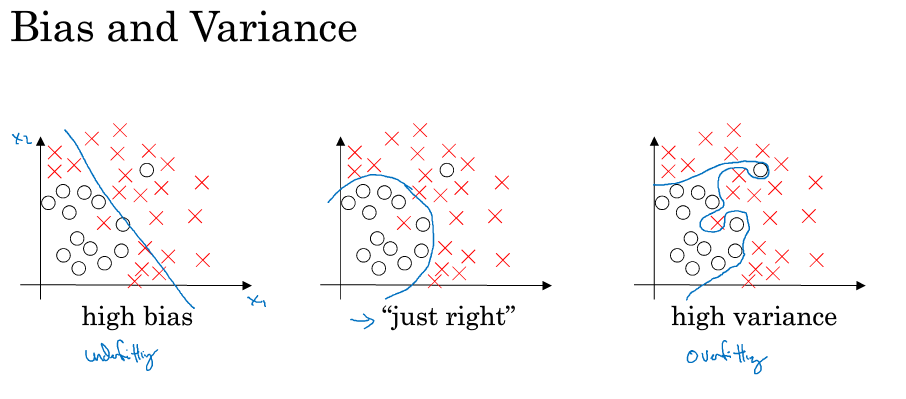
偏差和方差
偏差和方差的区别在数学上已经是老生常谈的问题.下图区别了偏差和方差,欠拟合和过拟合
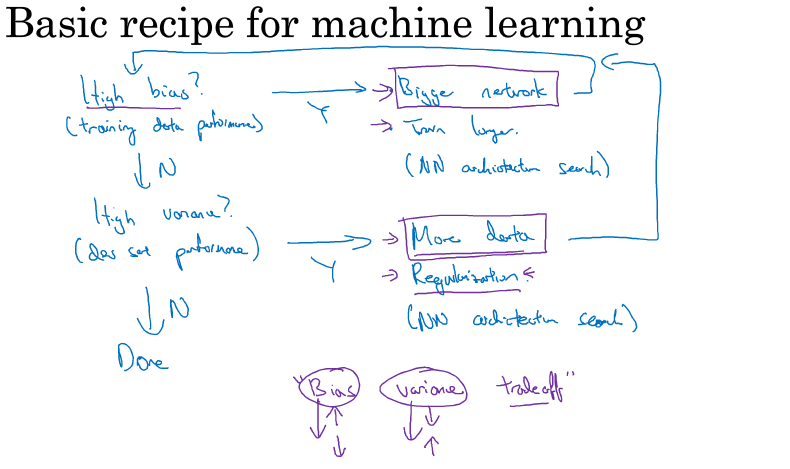
在深度学习搭建的迭代过程中需要确认偏差和方差的大小,以下为一种推荐路径:
正则化
正则化的目的是预防和减少过拟合,这里介绍了以下几种正则化方式:
- L2 正则化
- Drop out 正则化
- Data augument
- Early stopping
L2 正则化
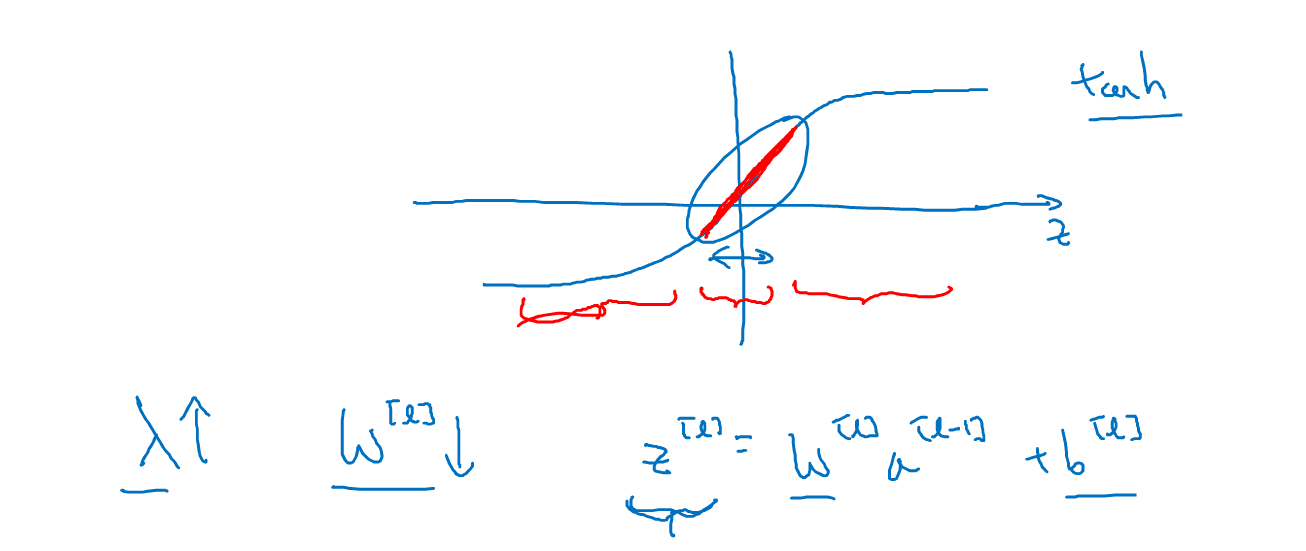
损失函数变化为: \(J(w, b) = \frac{1}{m}\sum L(y'^{i}, y^{i}) + \frac{\lambda}{2m}||w||^{2}\)
下图展示了具体原因,$\lambda$变大,w会相应变小,导致z变小,进而偏向中间线性的部分,进而相欠拟合的方向移动;反之则向过拟合的方向移动
 Dropout 正则化
Dropout 正则化
思路:结果不能完全依靠某个特征,所以需要随机的选择一些特征
成功应用:由于没有足够数据,会出现过拟合的现象,所以在计算机视觉广泛应用
缺点:损失函数不是well-defined. Data Augument
运用对图片进行旋转,翻转,截图,变形等操作来解决数据不足的问题.
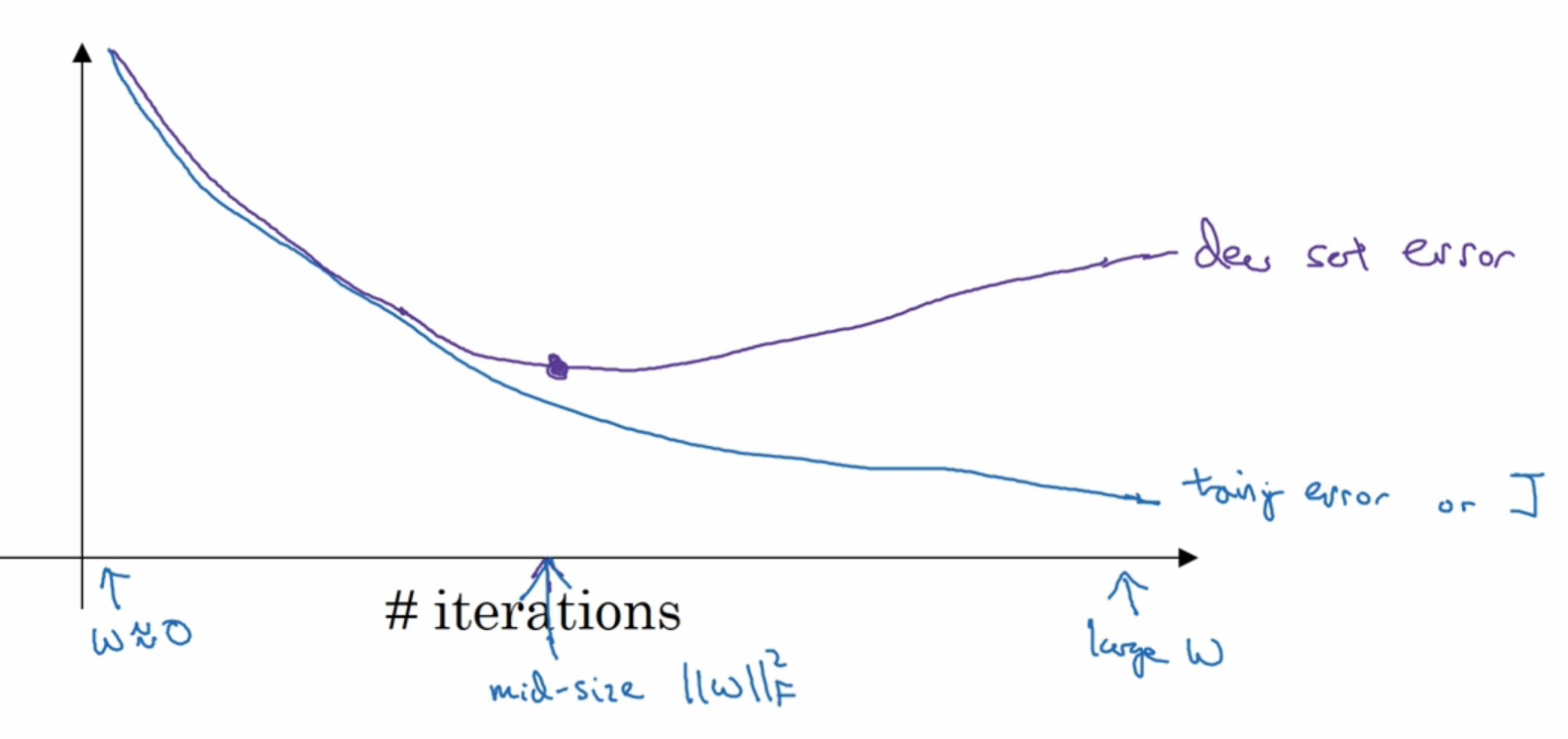
Early Stopping
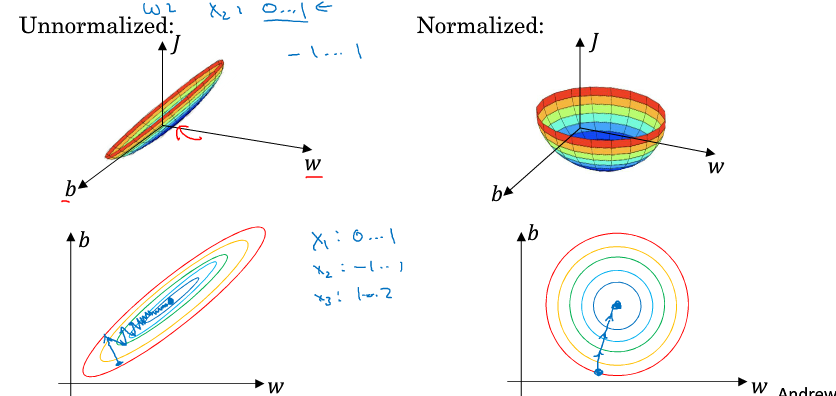
归一化输入
归一化输入可以使快速收敛
梯度消失和爆炸
w的初始化会影响到z进而影响到梯度的大小,若梯度太小则收敛会很缓慢,反之则有可能不收敛.举个例子说明梯度消失和爆炸:$0.5^{152}=0$, $1.5^{152}= \infty$.所以w的值(比如模)应该不能比1大很多,也不能比1小很多
解决办法:权重初始化
由$z = w^{1}a^{1}+w^{2}a^{2}+w^{3}a^{3}…w^{n}a^{n}$
设定$Var(w) = \frac{2}{n}$
从而初始化w时,乘以权重$\sqrt{\frac{2}{n^{[l-1]}}}$(ReLu函数的解决方案)
对于Tanh函数,一般采用Xavier initialize, 权重为: \(\sqrt{\frac{1}{n^{[l-1]}}}\)
Gradient Check (梯度检验)
梯度检测
思想很简单,就是微积分知识而已.
需要注意的几个问题:
- 只用于debug
- 计算dw时需要加一项
- 使用时需要关闭dropout
Optimization Algorithms
在本节中,首先引入了mini-batch梯度下降的概念,然后介绍指数加权平均的概念,之后介绍的动量梯度下降,RMSprop, Adam算法都有赖于这个概念.最后介绍了学习率递减和局部最优解的问题.
Summay
Momentum usually helps, but given the small learning rate and the simplistic dataset, its impact is almost negligeable. Also, the huge oscillations you see in the cost come from the fact that some minibatches are more difficult thans others for the optimization algorithm.
Adam on the other hand, clearly outperforms mini-batch gradient descent and Momentum. If you run the model for more epochs on this simple dataset, all three methods will lead to very good results. However, you’ve seen that Adam converges a lot faster.
Some advantages of Adam include:
- Relatively low memory requirements (though higher than gradient descent and gradient descent with momentum)
- Usually works well even with little tuning of hyperparameters (except $\alpha$)
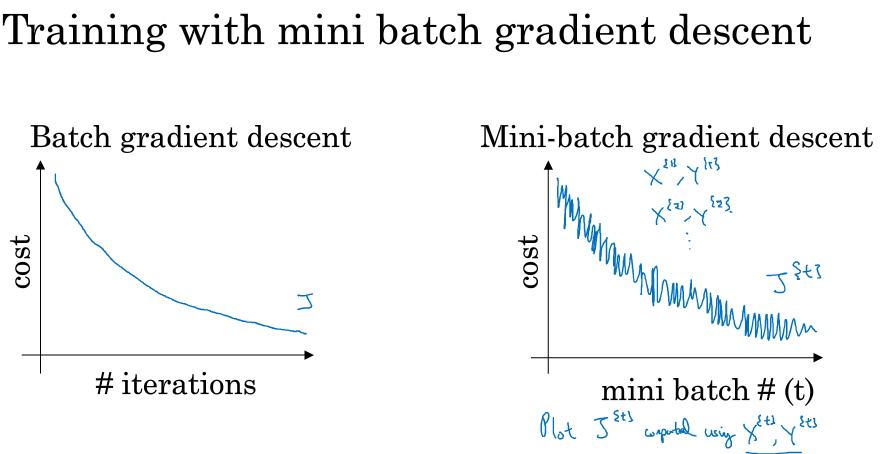
Mini batch 梯度下降
主要思想是:将整个opoch分为数个mini-batch.然后在对整个epoch的一次迭代中,会在所有的mini-batch里进行梯度下降计算,完成后进入下一次迭代.
损失函数会呈现如下趋势:
mini-batch size=
- 整个 $\longrightarrow$ Batch GD
- 1 $\longrightarrow$ stochastic GD
- m $\longrightarrow$ mini batch GD
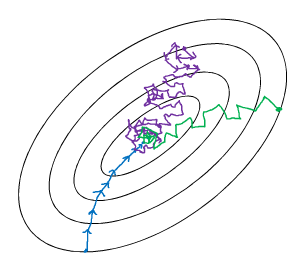
如下图,1为最下面,直指目标,然而耗时,2是中间的,完全失去了向量化所带来的速度:
有一个超参数:mini batch size 一般为64, 128, 256, 512
动量梯度下降
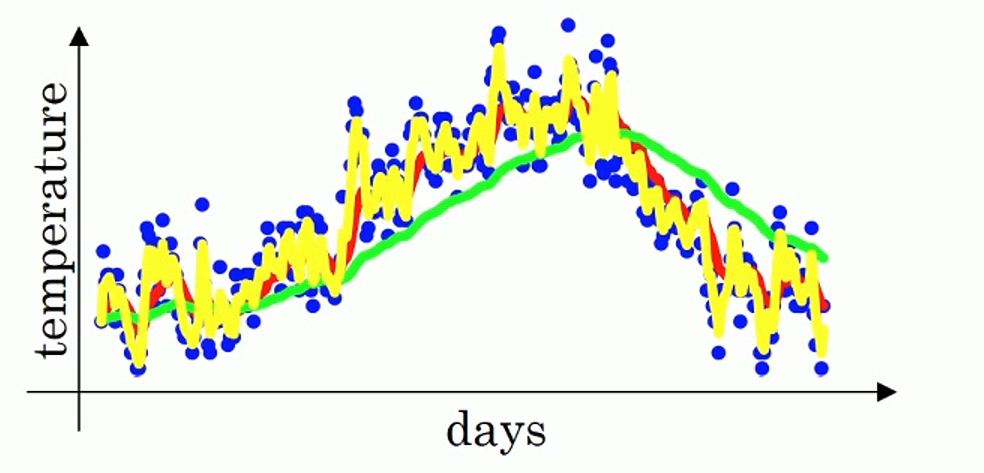
指数权重平均
课程中举了伦敦温度作为例子,这个操作类似于平均前几天的值作为今天的值,不过这个技术使用了加权平均,这样使线的走势更加的平滑.如下图
$\theta_t$ 为单独t时的值
$\theta_0 = 0$, $v_t = \beta v_{t-1} + (1-\beta)\theta_t$
相当于加权平均前$\frac{1}{1-\beta}$天
误差纠正的问题:
如下图,在初始的几个点处,由于$\theta_0=0$, 所以初始点偏小,需要加上一下误差纠正: \(v_t = \frac{v_t}{1-\beta^t}\)
动量梯度下降
既然指数权重平均可以平滑波动,在梯度下降中可以利用这个技术使梯度下降过程中的波动更加平滑.
实现如下: \(v_{dw}=\beta v_{dw} + (1-\beta)dw\) \(v_{db}=\beta v_{db} + (1-\beta)db\) \(w = w - \alpha v_{dw}\) \(b = b - \alpha v_{db}\) 超参数有: $\alpha$. $\beta$
RMSprop
RMS:root mean square
RMSprop的具体思路和流程如下
其是增加水平方向的速度,减少竖直方向的波动大小(具体还待探究)
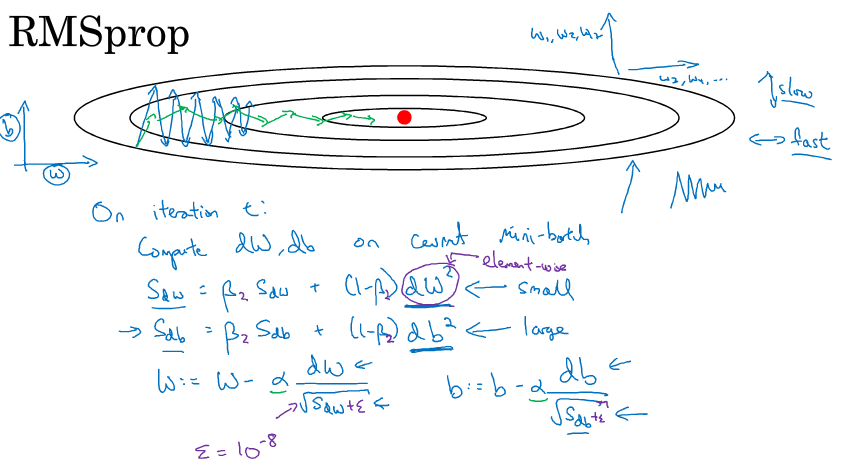
\(S_{dw}=\beta_2 S_{dw} + (1-\beta_2)dw^2\) \(w = w - \alpha \frac{v_{dw}}{\sqrt{S_{dw} }+ \epsilon}\) $\epsilon$ 的作为为防止分母为0,一般取值$10^{-8}$
Adam: adaptive moment estimation
主要思想是将momentum和RMSprop结合起来
算法如下:

其中的超参数为:
- $\alpha$ 学习率,需要确定
- $\beta_1$ 动量梯度下降的参数,一般0.9
- $\beta_2$ RMSprop的参数,一般0.9
- $\epsilon$, RMSprop的参数,一般$10^{-8}$
Adam 优化算法
学习率衰减
通过衰减学习率来使其更快收敛
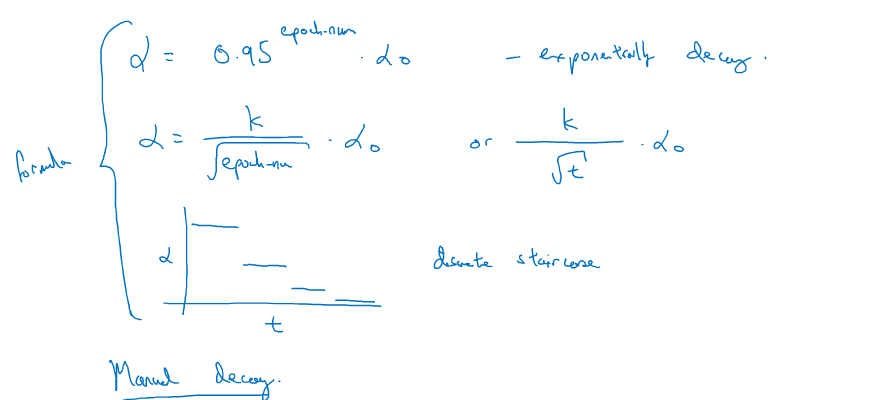
超参数调整,正则化和优化
前一节介绍了几种加速梯度下降的方法,并且引入了数个超参数.本节主要关注于超参数的调整,正则化和优化.
超参数调整
分为两个阶段调整:
class 1: $\alpha$
class 2: $\beta$, # of layers, # of neutrons…
两个建议:
- 随机选取不要网格选取
- 大间隔选取到小间隔选取
选择合适的坐标来选取超参数:
- $\alpha$: r = -4*np.random.rand(), $\alpha=10^{r}$
- $\beta$(指数权重平均因子): $1-\beta$: 0.1, 0.01, 0.001
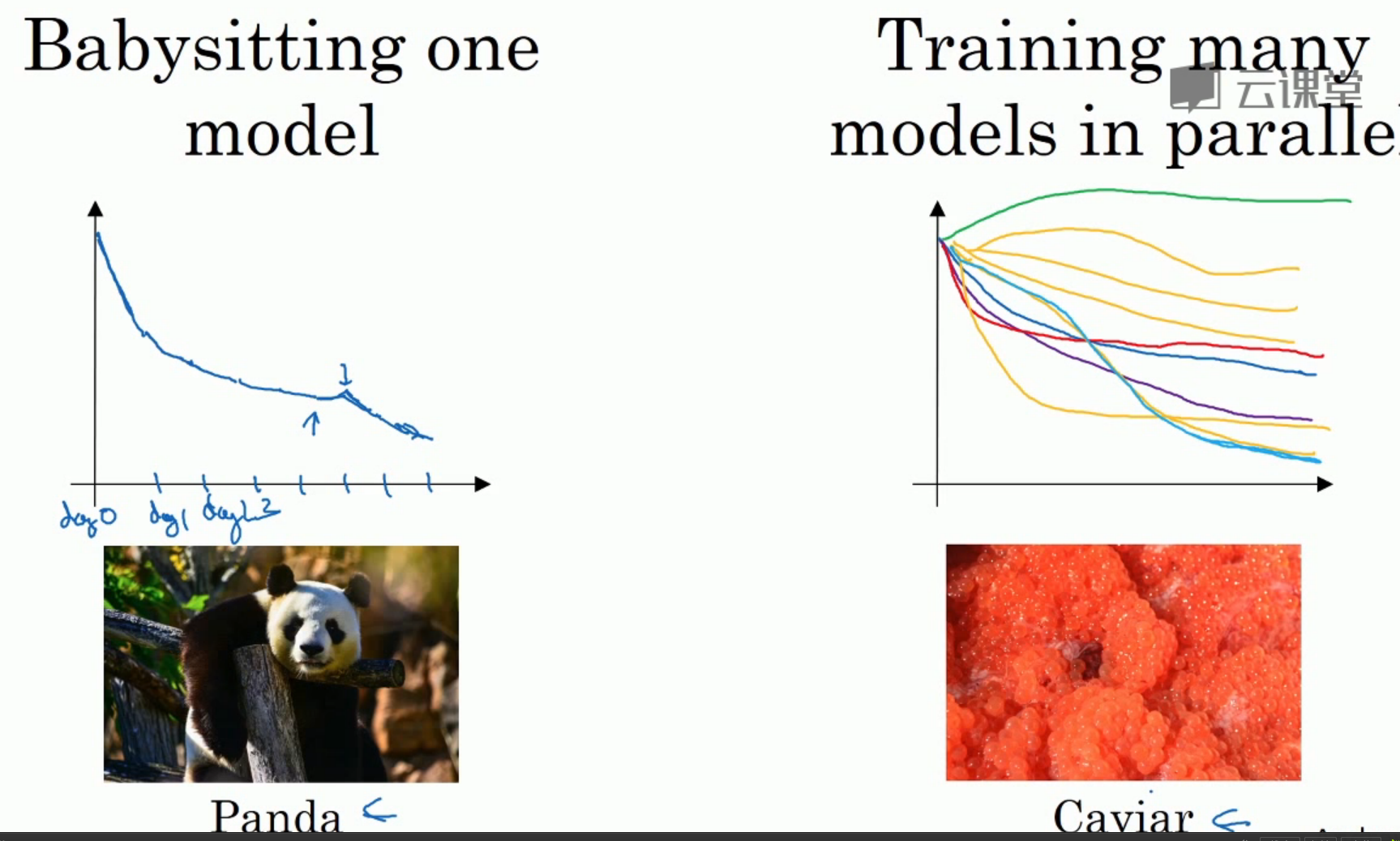
模型实际训练(由你掌握的计算资源决定):
Batch Normalization
之前介绍了输入归一化,此部分为batch归一化,操作于隐藏层.具体深入之前首先要介绍一个概念:covariate shift,它指现有经验无法适应新的环境.Batch归一化的思想是这样的:通过固定Z的平均值和方差,来消除covariate shift的现象. 简单的理解就是:通过这个技术来只保存通用比例信息,而乎略了有关大小的个体信息,进而得到一般化的模型
如下图展示:
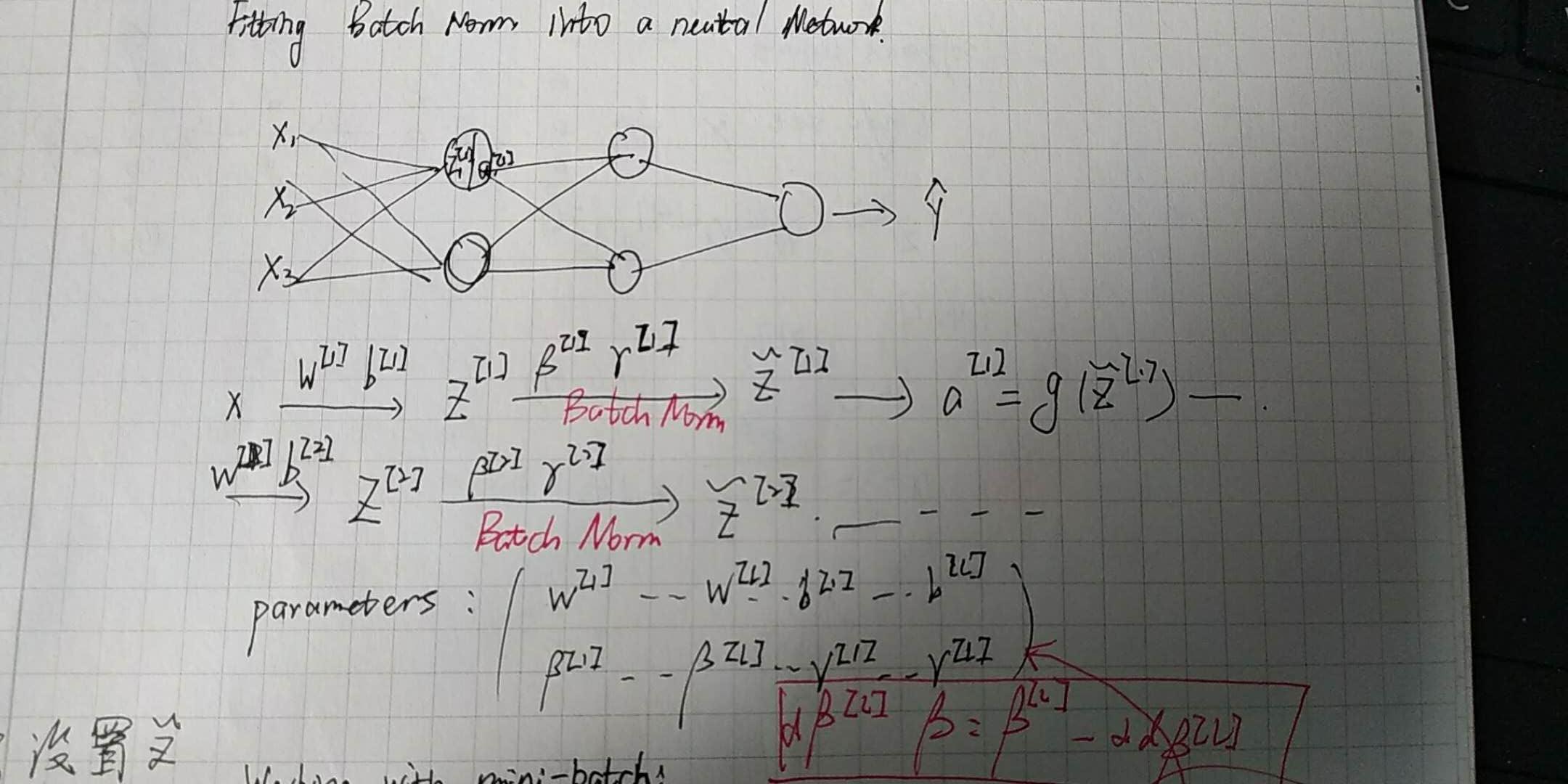
公式如下: \(\mu = \frac{1}{m}\sum_i z^{i}\) \(\sigma = \frac{1}{m}\sum(z^{i}-\mu)^2\) \(z^{i}_{norm}=\frac{z^{i}*\mu}{\sqrt{\sigma^2 + \epsilon}}\) \(\tilde{z}^{i} = \gamma z^i_{norm} + \beta\) 需要注意的是:$b$的存在变得没有意义,因为在$Z_{norm}$的计算过程中b会被消去,进而$\gamma$会取代b的作用.$\gamma$, $\beta$使你可以设置其的平均值和方差
梯度下降过程展示:

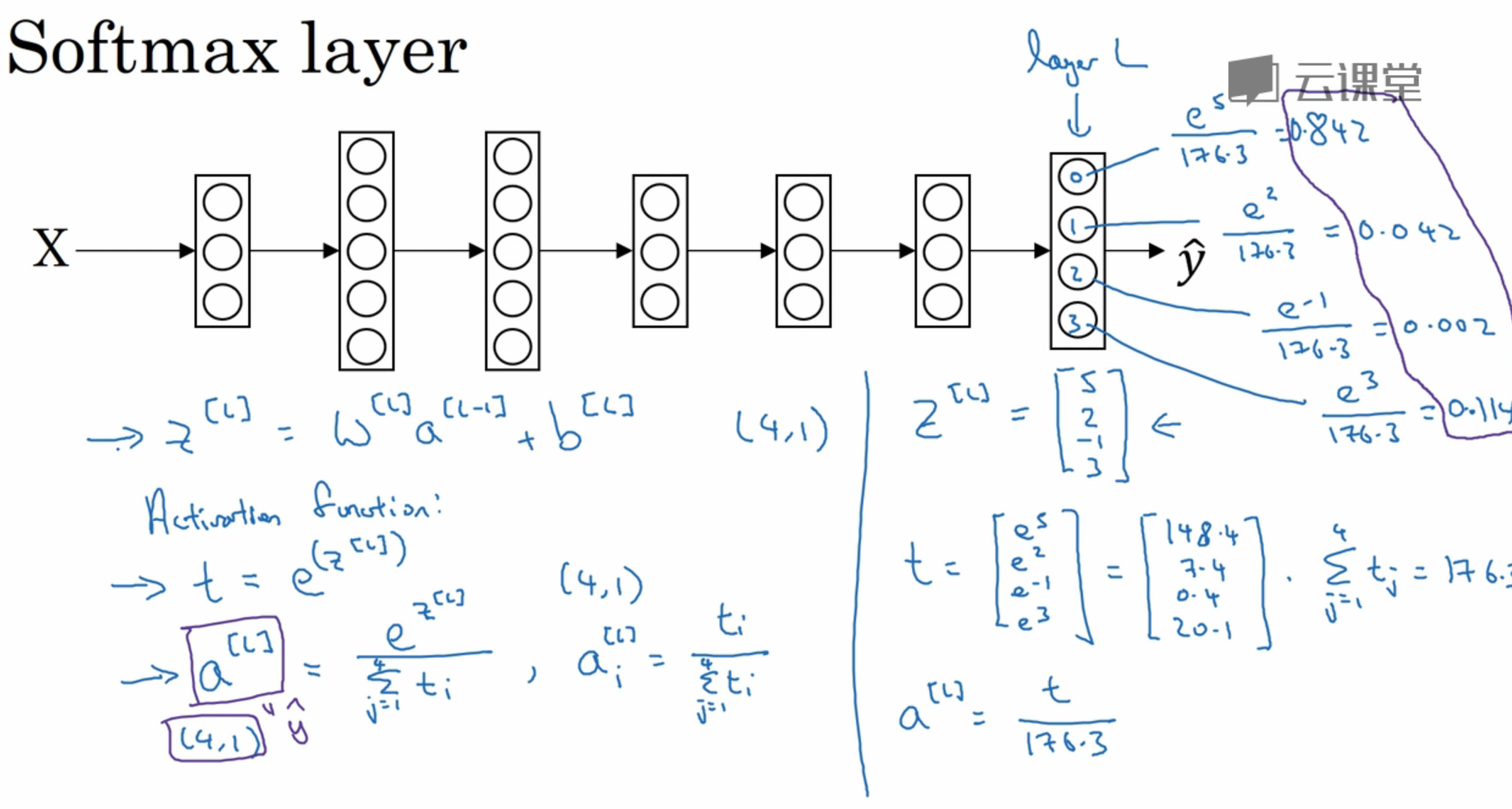
SoftMax regression
应用于多类分类问题
过程如下图
 损失函数实现如下图:
损失函数实现如下图:

总结
本系列的第一本课程搭建了深度学习的基础框架.这门课程深入介绍了一些技术和优化算法,同时引入和很多超参数,随后介绍重点介绍勒