笔者在2017年10,11月期间学习了Cousera上吴恩达老师的深度学习课程系列的前四个课程,并拿到证书.趁假期回头分析总结下,希望能有更深的理解.
这门课主要介绍了神经网络的基础知识.首先大致介绍了神经网络的种类的应用场景,神经网络技术为何会兴起,然后课程一步步从线性回归,逻辑回归,进而过渡到浅层神经网络,深层神经网络.这个过程中介绍了损失函数,梯度下降,反向传播,激活函数等概念.
- 神经网络种类和应用前景
- 为何深度学习会兴起
- 从线性回归到逻辑回归
- 梯度下降
- 神经网络概览和表示
- 神经网络的向量表示
- 激活函数(Activation function)
- 梯度下降(正向传播和反向传播)
- 随机初始化
- 深层神经网路
- 总结
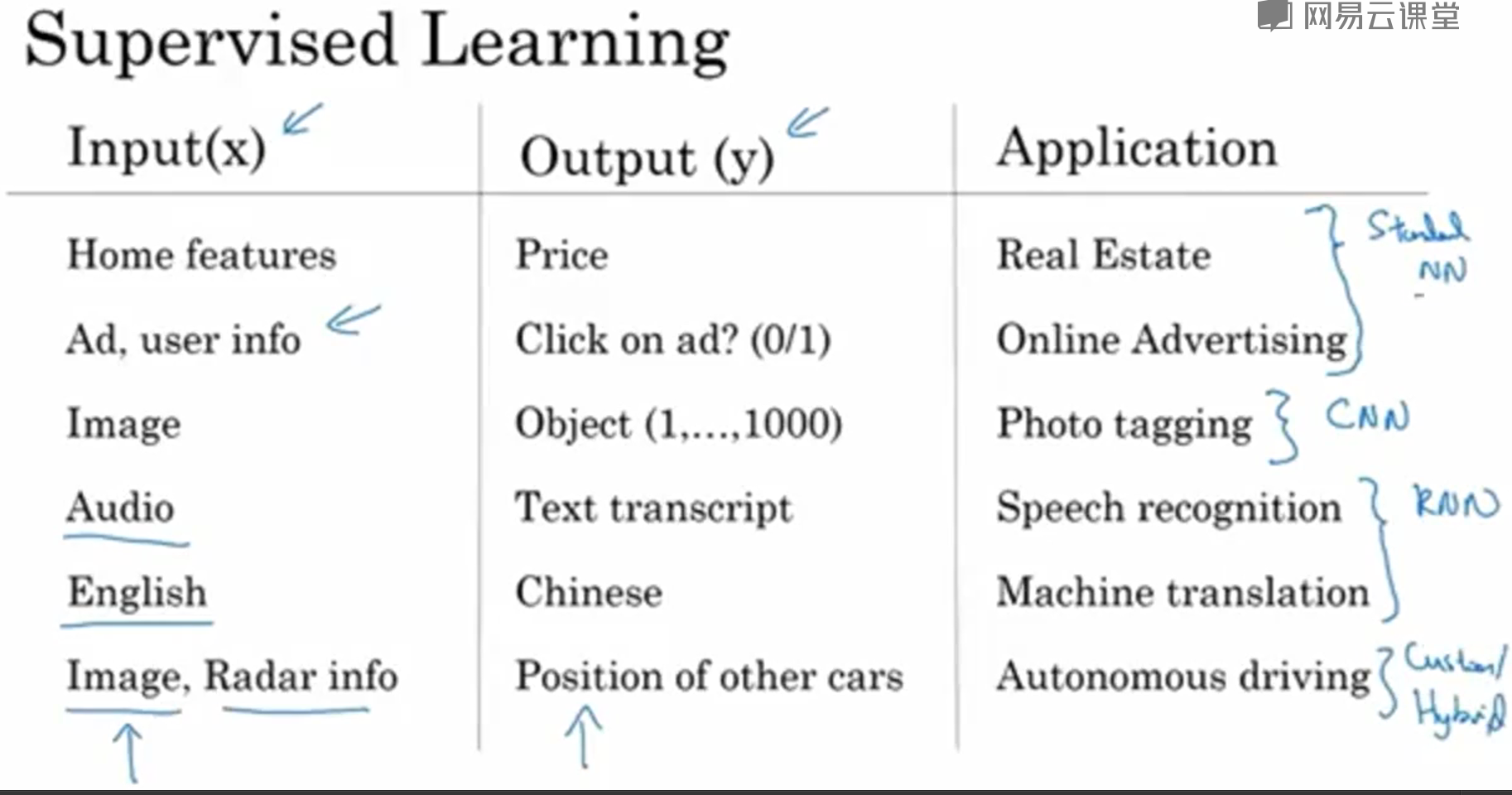
神经网络种类和应用前景
下图可看出标准神经网络,卷积神经网络,递归神经网络的主要应用场景
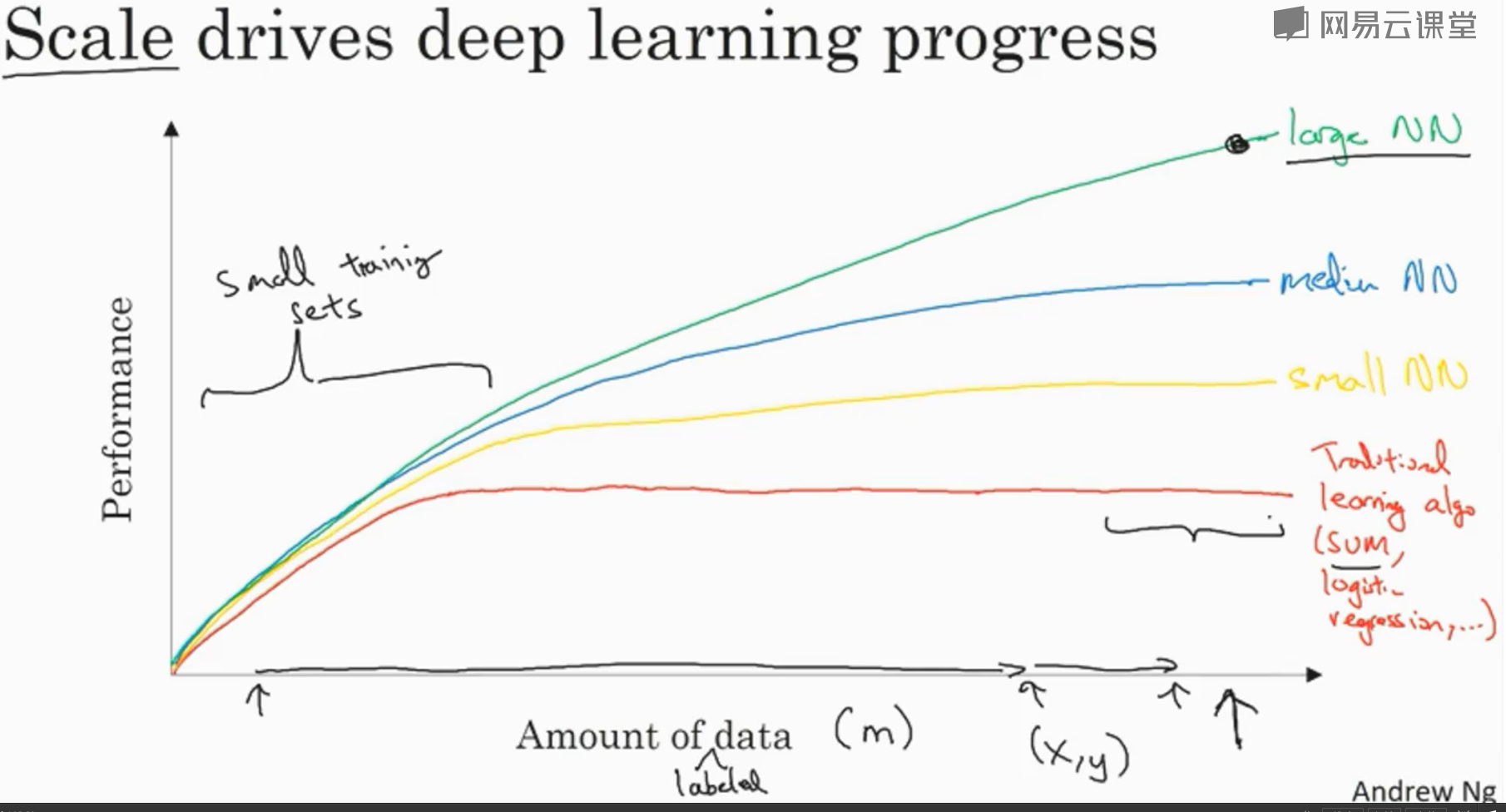
为何深度学习会兴起
答案是数据的增加和积累
从线性回归到逻辑回归
算法
- Given X, want $y_{predict}$,
-
Param $w=R^n$, $b\in R$
- 线性回归 Output: $y_{predict}=w^Tt + b$
- 逻辑回归 Output: $y_{predict} = \sigma(w^Tt +b)$ where $\sigma(z) = \frac{1}{1 + e^{-z}}$
-
损失函数
一般想法为$L = \frac{1}{2}(y’-y)^2$, 但这个函数在梯度下降过程中很容易困于局部最值,于是选择以下损失函数:
Loss function(single sample):
- $L(y’, y)=-(ylog(y’) + (1-y)log(1-y’))$
Cost function(entir train set):
- $J(w, b) = \frac{1}{m}\sum_{i=1}^{n}L(y’^{(i)}, y^{(i)})$
原因解释为:
若P(y/x)表示值为y的概率,则\(P(y/x)=y'^y(1-y')^{(1-y)}\) 则: \(logP(y/x)=ylogy'+(1-y)log(1-y')\) 结论:损失函数最小就意味着损失函数最小
对于一个数据集: \(P(y/x)=P(y^{1}/x^{1}) + ... P(y^{m}/x^{m})\) \(log(P(y/x))=log(P(y^{1}/x^{1})) + ... log(P(y^{m}/x^{m}))\)
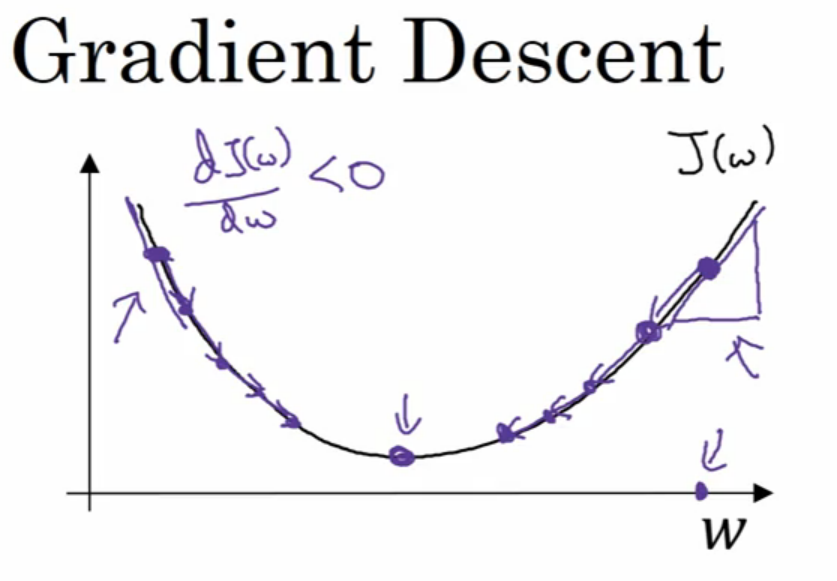
梯度下降
梯度下降方法在数值分析中是一种很常见的求最值的方法.通过不断向最值靠近来逼近最优值,然而需要注意学习率(learning rate)大小的选取,后面章节中会具体讨论学习率大小选取的技巧.
下图是梯度下降概念的展示:
 在课程中还提到用计算图(Computation graph)来展示逻辑回归中梯度下降的实现.如下图:
在课程中还提到用计算图(Computation graph)来展示逻辑回归中梯度下降的实现.如下图:

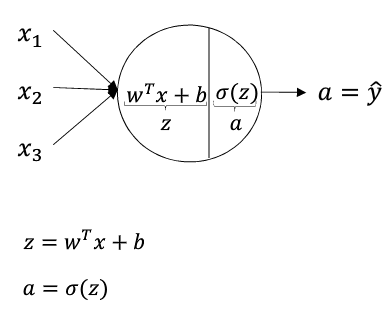
神经网络概览和表示

如下图为一个两层的神经网路:输入层,中间层(输出层不包括).
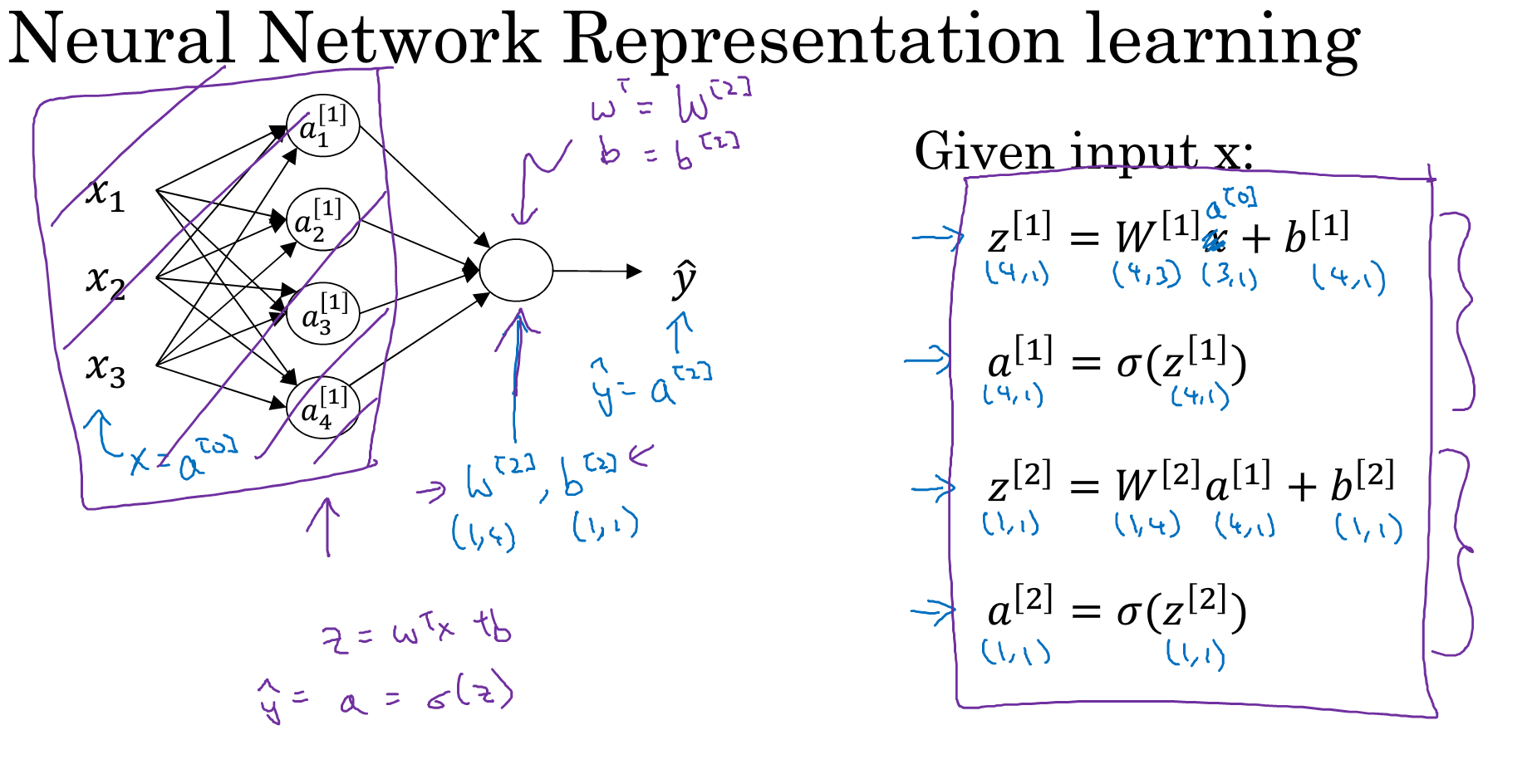 需要注意的是:每个圆圈都代表一个神经元,每个神经元中都会进行两步操作,如第二个图显示.
需要注意的是:每个圆圈都代表一个神经元,每个神经元中都会进行两步操作,如第二个图显示.
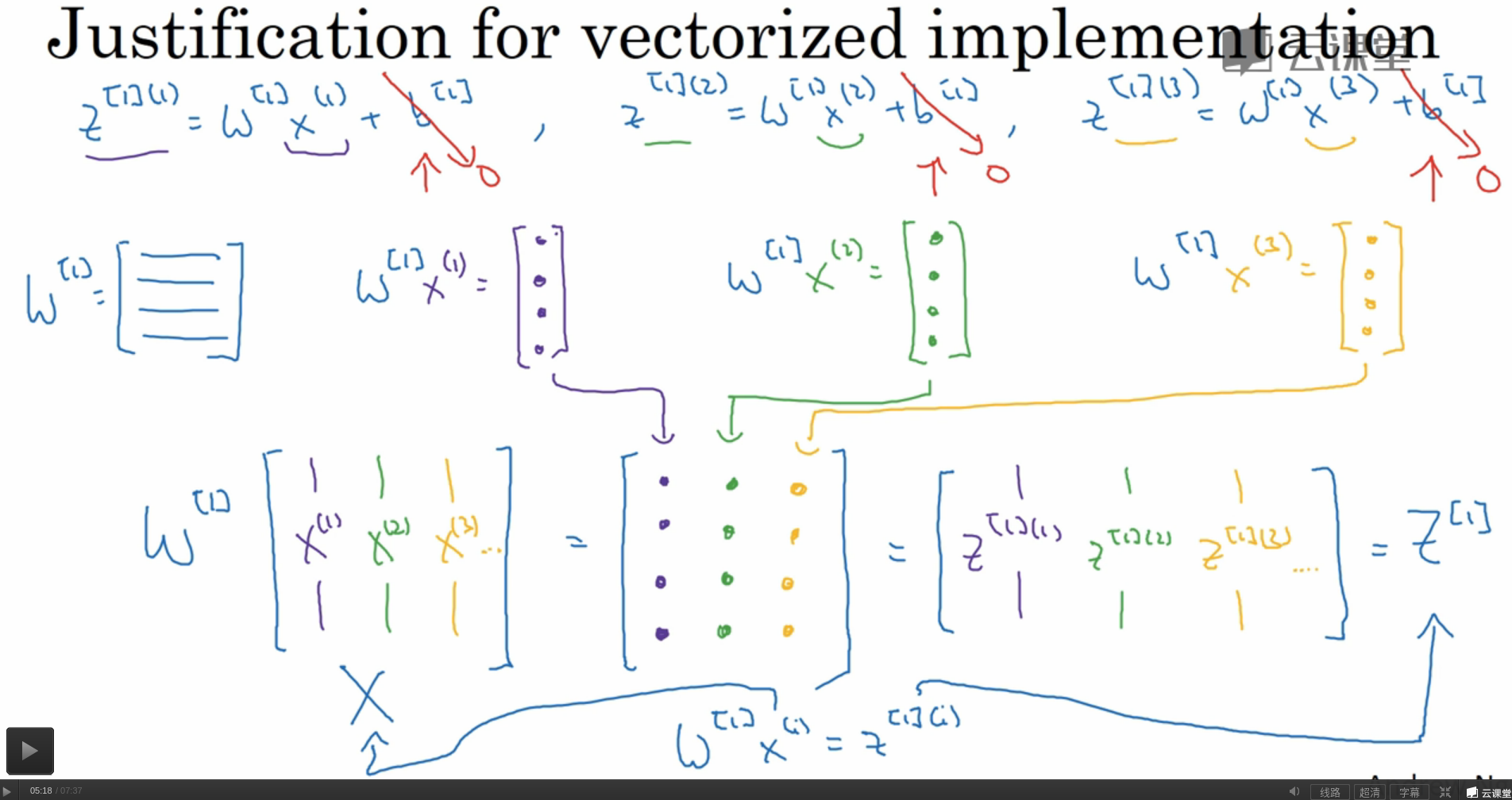
神经网络的向量表示
由于实例,特征,层数,每层神经元数目都可能不是一个,问题变成了多维,难于理解.神经网络的向量化实现可以大大简化问题.
结合上部分图一,有三个量在向量化中需要注意:
h: 这一层的神经元数
$n_x$: 特征的数目
m: 实例的数目
如下图所示,具体形状如下:
(h, $n_x$)*($n_x$, m) $\longrightarrow$ (h, m) $\longrightarrow$ (h, m)
以上还牵涉到Python语法中的传播特性,笔者会在之后补充这部分的内容
激活函数(Activation function)
课程中介绍了四种常见的激活函数,如下图:
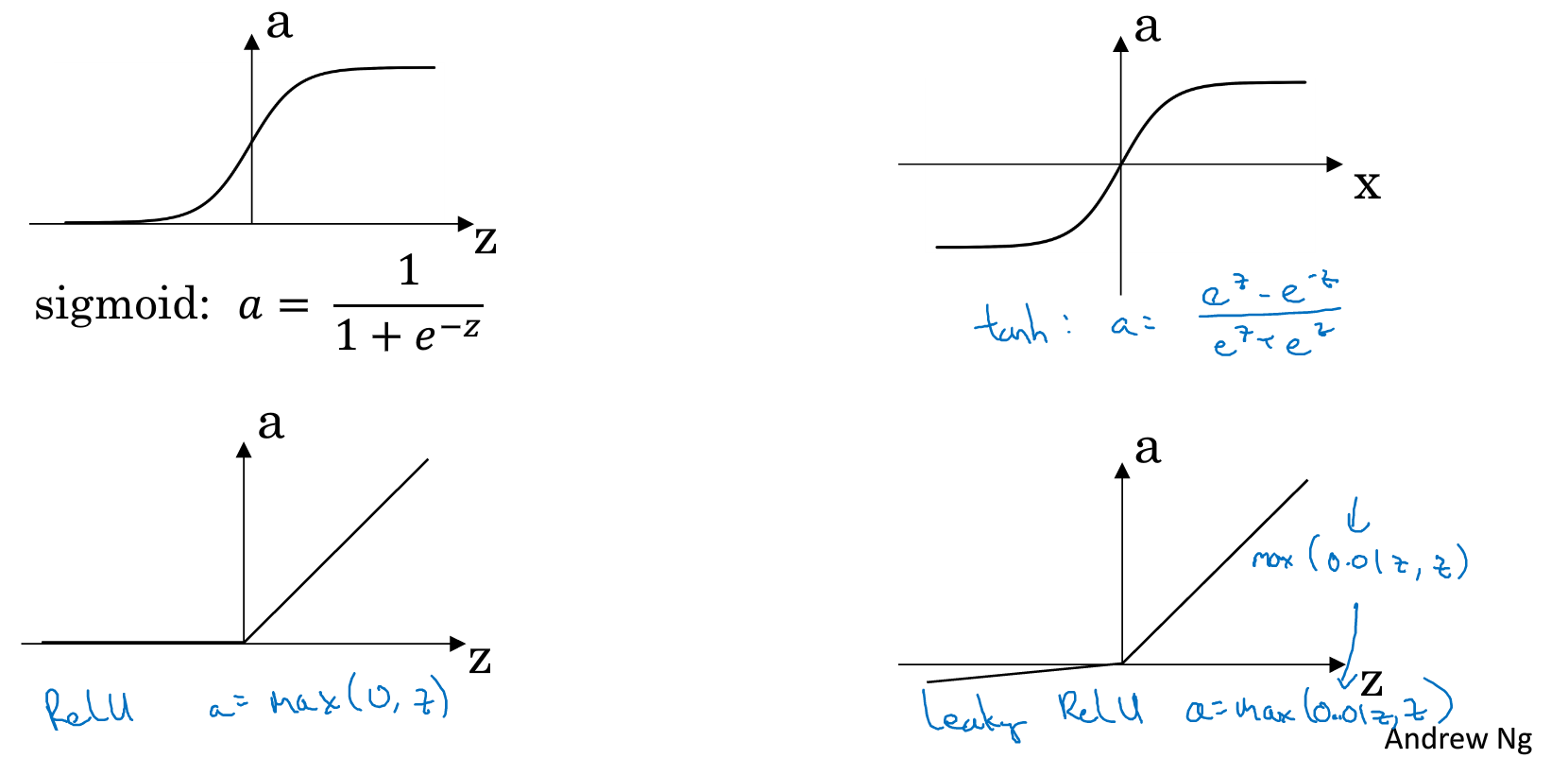
同时给出了各个函数的优缺点如下表,同时给出建议:若是不确定那个比较合适,那就都尝试一下
| Sigmoid | Tanh | ReLU | Leaky ReLU | |
|---|---|---|---|---|
| 缺点 | x较大或较小时,值的变化不大 | 同Sigmoid | x<0时斜率为0 | 很少被采用 |
| 优点 | 一般只用于二元问题的输出层 | 比较常用性能高于sigmoid | 常用的中间层函数 |
这些函数都是非线性函数,如若是线性函数,则输出会是输入的线性函数,则隐藏层作用全无
梯度下降(正向传播和反向传播)
以下为反向传播的总结:

随机初始化
由上知道需要初始化的有两个矩阵: w 和 b
如若初始化为0矩阵$\longrightarrow$ 隐藏层中对称,每个神经元都得到同样结果$\longrightarrow$ 不能收敛
为避免这个结果,随机初始化w即可,同时比较大的w会导致比较大的z,结合tanh和sigmoid函数的形状特点.比较小的w比较适合.
于是: w = 0.01*np.random.randn((x, y))
注意:
-
np.random.rand: choose from uniform distribution
-
np.random.randn: choose from normal distribution
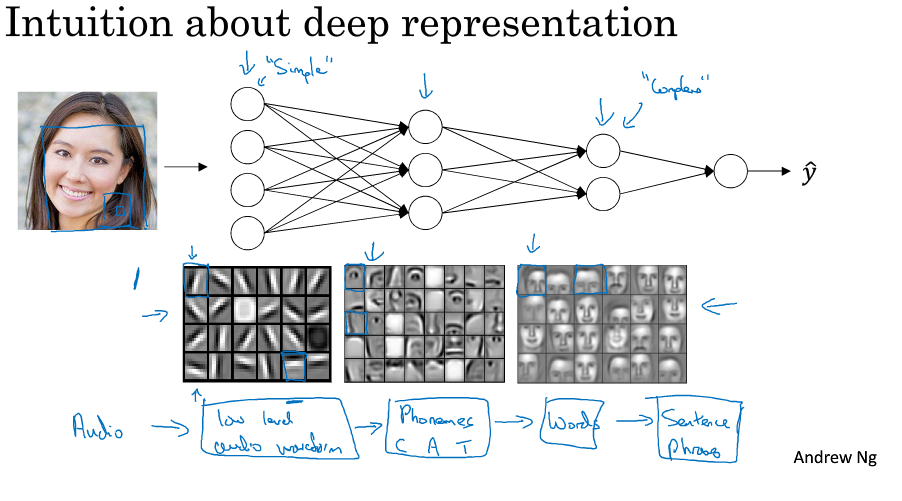
深层神经网路
深层的神经网络会有更多的参数,其过程可理解为从提取简单信息开始到提取高级复杂信息,下如是一个展示
参数和超参数
参数:
- $w^{[1]} d^{[1]}w^{[2]} d^{[2]}$等
超参数:
- 学习率
- 迭代次数
- 神经网络层数
- 每层单元数
- 激活函数的选择
- 其他方法如: momentam, minBatch等技术的选择
正式由于参数众多,深度学习的正确应用需要经验,需要不断试错
总结
本门课程解释了在Machine learning 课程上未解释清楚的概念,整体上介绍神经网络,同时介绍了一些基本概念和技术如损失函数,激活函数,梯度下降,正向传播和反向传播等.