Introduction
本节总结如下排序方法:
- Bubble sort 冒泡排序
- Selection sort 选择排序
- Insertion sort 插入排序
- Shell sort 希尔排序
- Merge sort 归并排序
- Quick sort 快速排序
- heap sort 堆排序
Summary
以上这6种排序方法都为比较排序, 总体总结这几种排序:
- 冒泡排序的过程中会不断的交换元素, 然而选择排序可以说是冒泡排序的改进版, 它相当于选择了前面数列中的最大值, 省却了在过程中更换位置的操作;
- 插入排序相当于把过程反过来, 假设之前的列表已经排好序, 然后把新元素插入其中, 而希尔排序是插入排序的改进版, 它通过先把列表分成几个小列表, 在小列表内部进行插入排序, 最后对大列表进行插入排序, 以此达到较快的排序;
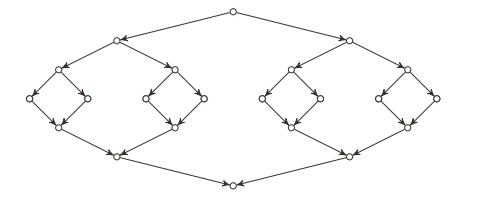
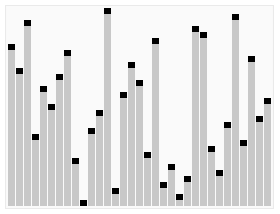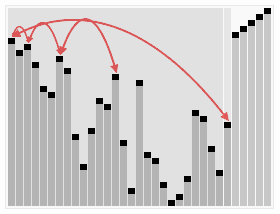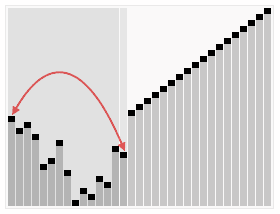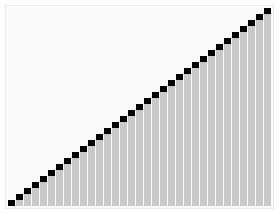
- 归并排序和快速排序用到分治法的思想, 如下图(来源:Python algorithms)为分治法的一个节点展示, 快速排序在前一半(dividing)实现, 而归并排序在后一半(combining)实现.
- 堆排序通过使用完全二叉树来实现排序
之后还将介绍到非比较排序,主要有计数排序,基数排序,桶排序等
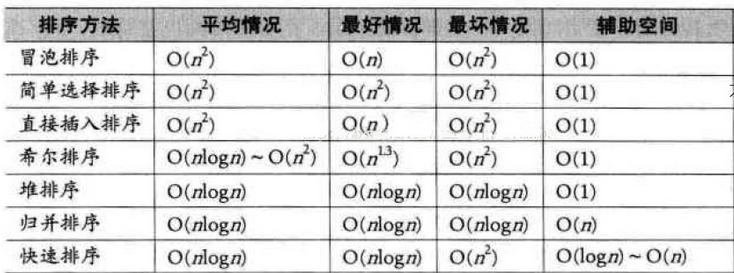
排序算法性能如下:
Bubble Sort
复杂度为$O(n^2)$
算法:
- 1.比较相邻的元素,若第一大于第二,就交换他们
- 2.对每一对相邻元素进行相同操作,使最大元素到最后.
- 3.除却后部排好序的元素,然后再次进行1,2步操作
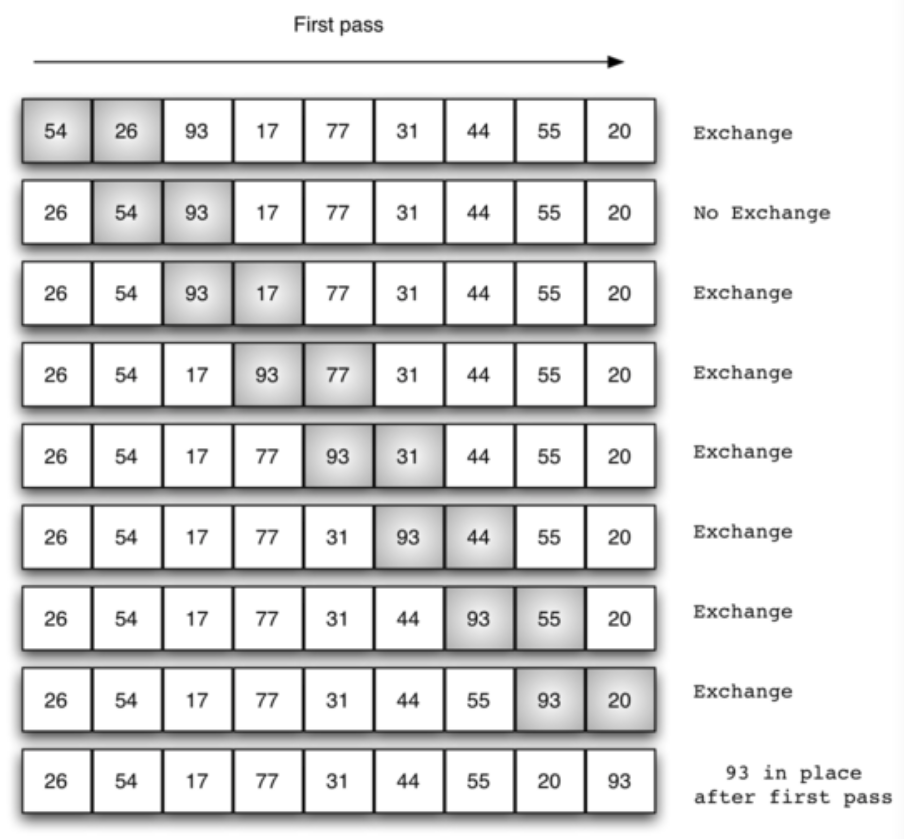
两个两个比较,从头到尾,手中总是拿着到目前为止最大的那个,第一轮过去让最大的元素沉到列表的最后面。依次进行。示意图如下:
def bubbleSort(alist, ascending=True):
for unordered_boundary in range(len(alist)-1,0,-1):
for i in range(unordered_boundary):
if ascending:
if alist[i]>alist[i+1]:
alist[i], alist[i+1] = alist[i+1], alist[i]
else:
if alist[i]<alist[i+1]:
alist[i], alist[i+1] = alist[i+1], alist[i]
alist = [54,26,93,17,77,31,44,55,20]
bubbleSort(alist, ascending=True)
print(alist)
bubbleSort(alist, ascending=False)
print(alist)
[17, 20, 26, 31, 44, 54, 55, 77, 93]
Selection sort
复杂度就比较来言,和冒泡排序一样为$O(n^2)$,然而交换的次数大大减少,所以运行速度更快。
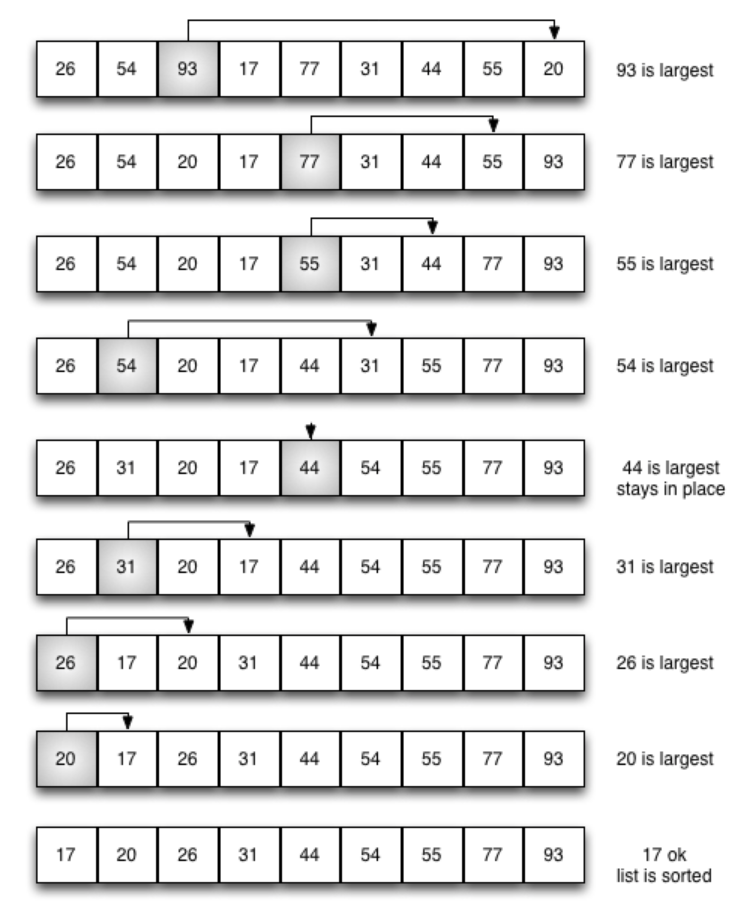
在剩下的表中,遍历发现最大的元素,然后把它放在末端。
def selection_sort(lst) -> None:
length = len(lst)
for unordered_right_boundary in range(length-1, 0, -1):
max_idx = 0
for idx in range(0, unordered_right_boundary+1):
if lst[idx] > lst[max_idx]:
max_idx = idx
lst[max_idx], lst[unordered_right_boundary] = lst[unordered_right_boundary], lst[max_idx]
alist = [54,26,93,17,77,31,44,55,20]
selection_sort(alist)
print(alist)
[17, 20, 26, 31, 44, 54, 55, 77, 93]
Insertion sort
插入排序(insertion sorting):假设前面的元素已经排好序,将这个元素插入前面的元素,为提高速度,可采用二分查找来插入.
复杂度的问题:
算法最坏复杂度为$O(n^2)$,最好为$O(n)$
# normal insertion sort algorithm
def insertion_sort(lst):
for idx in range(1, len(lst)):
current_value = lst[idx]
position = idx
while position > 0 and lst[position-1] > current_value:
lst[position] = lst[position-1]
position -=1
lst[position] = current_value
# insertion sort with binary search
def insertion_sort_binary_search(lst):
for idx in range(1, len(lst)):
current_value = lst[idx]
position = idx
lower = 0
higher = position - 1
while higher >= lower:
mid = (higher + lower) / 2
if lst[mid] > current_value:
higher = mid -1
else:
lower = mid + 1
# print lower
# print higher
while position > lower:
lst[position] = lst[position-1]
position -=1
lst[position] = current_value
# print lst
Shell sort
相当于对列表进行了前处理,使得总的复杂度降低。
前处理:列表被分割成几个小的列表,每个列表内部进行插入排序
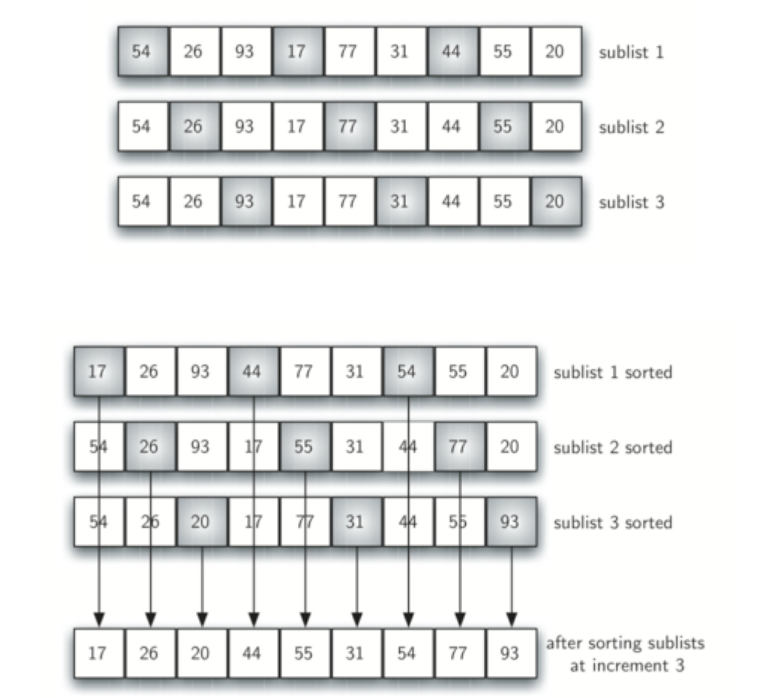
选用不同的gap进行处理,最后一个的gap为1,得到最后的结果。如下示例代码:
def shellSort(alist):
sublistcount = len(alist)//2
while sublistcount > 0:
for startposition in range(sublistcount):
gapInsertionSort(alist,startposition,sublistcount)
print("After increments of size",sublistcount,
"The list is",alist)
sublistcount = sublistcount // 2
def gapInsertionSort(alist,start,gap):
for i in range(start+gap,len(alist),gap):
currentvalue = alist[i]
position = i
while position>=gap and alist[position-gap]>currentvalue:
alist[position]=alist[position-gap]
position = position-gap
alist[position]=currentvalue
alist = [54,26,93,17,77,31,44,55,20]
shellSort(alist)
print(alist)
('After increments of size', 4, 'The list is', [20, 26, 44, 17, 54, 31, 93, 55, 77])
('After increments of size', 2, 'The list is', [20, 17, 44, 26, 54, 31, 77, 55, 93])
('After increments of size', 1, 'The list is', [17, 20, 26, 31, 44, 54, 55, 77, 93])
[17, 20, 26, 31, 44, 54, 55, 77, 93]
Merge sort
合并排序(merge sort): 二路排序,将原始数据分为两部分,分别进行排序,然后将各自集合并. 典型分治法测略.
- Split
- Merge
时间复杂度:
Split 二分log(n); Merge 每个元素都会被放入排序好的list中,每个需要n步.
所以总的复杂度为$O(nlogn)$ 归并排序复杂度推倒还不大清楚
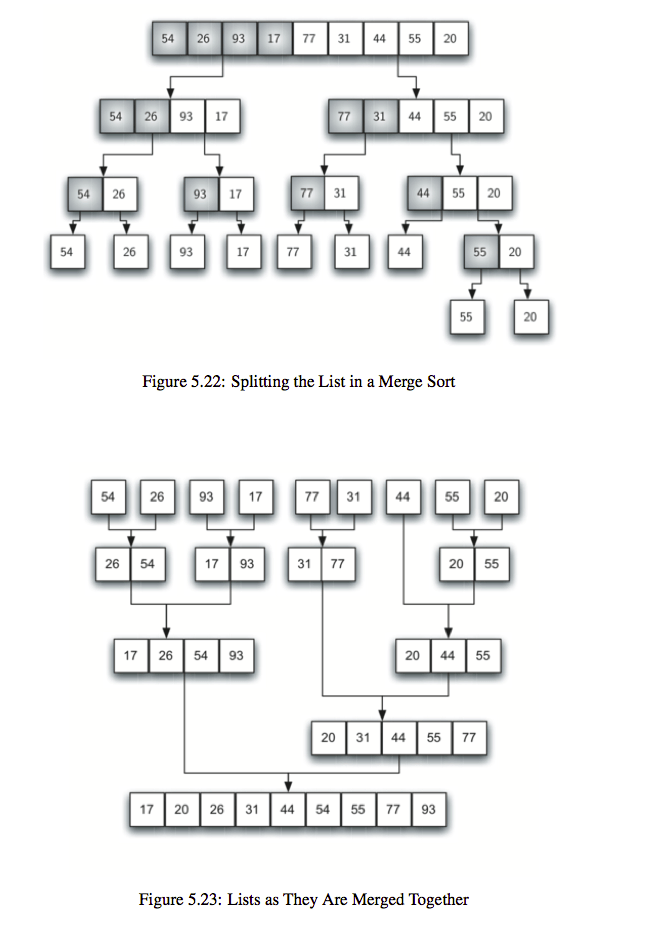
def mergeSort(lst) -> None:
length = len(lst)
if length <= 1:
return
else:
mid = length // 2
left_half = lst[:mid]
right_half = lst[mid:]
mergeSort(left_half)
mergeSort(right_half)
left_idx = 0
right_idx = 0
total_idx = 0
while left_idx<mid and right_idx<length-mid:
if left_half[left_idx] < right_half[right_idx]:
lst[total_idx] = left_half[left_idx]
left_idx += 1
else:
lst[total_idx] = right_half[right_idx]
right_idx += 1
total_idx += 1
while left_idx < mid:
lst[total_idx] = left_half[left_idx]
total_idx += 1
left_idx += 1
while right_idx < length-mid:
lst[total_idx] = right_half[right_idx]
total_idx += 1
right_idx += 1
alist = [54,26,93,17,77,31,44,55,20]
mergeSort(alist)
print(alist)
Quick sort
- 选择最后一个元素作为基准
- 之前所有元素和基准元素比较,分为两部分
- 对每部分进行1,2操作
复杂度:O(nlogn)
以下有两种方法实现快速排序
- index i&j 从左端开始
- index leftMark, rightMark 从两端同时开始
# 第一种方法
def partition(arr, firstIndex, lastIndex):
i = firstIndex - 1
for j in range(firstIndex, lastIndex):
if arr[j] <= arr[lastIndex]:
i += 1
arr[j], arr[i] = arr[i], arr[j]
# print 'j is ' + str(j)
# print arr
arr[i+1], arr[lastIndex] = arr[lastIndex], arr[i+1]
return i
def QuickSort(arr, firstIndex, lastIndex):
if firstIndex < lastIndex:
divIndex = partition(arr, firstIndex, lastIndex)
QuickSort(arr, firstIndex, divIndex)
QuickSort(arr, divIndex+1, lastIndex)
else:
return
第二种方法:
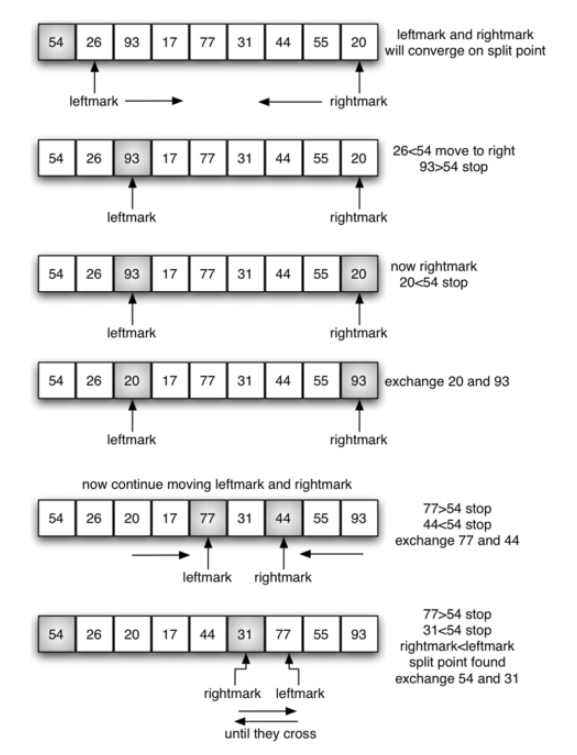
# 第二种方法
def quickSort(alist):
quickSortHelper(alist,0,len(alist)-1)
def quickSortHelper(alist,first,last):
if first<last:
splitpoint = partition(alist,first,last)
quickSortHelper(alist,first,splitpoint-1)
quickSortHelper(alist,splitpoint+1,last)
def partition(alist,first,last):
pivotvalue = alist[first]
leftmark = first+1
rightmark = last
done = False
while not done:
while leftmark <= rightmark and alist[leftmark] <= pivotvalue:
leftmark = leftmark + 1
while alist[rightmark] >= pivotvalue and rightmark >= leftmark:
rightmark = rightmark -1
if rightmark < leftmark:
done = True
else:
temp = alist[leftmark]
alist[leftmark] = alist[rightmark]
alist[rightmark] = temp
temp = alist[first]
alist[first] = alist[rightmark]
alist[rightmark] = temp
return rightmark
alist = [54,26,93,17,77,31,44,55,20]
quickSort(alist)
print(alist)
[17, 20, 26, 31, 44, 54, 55, 77, 93]
Heap Sort
堆排序时利用堆这种数据结构(这里运用大根堆), 通过无序区的大根堆寻找最大元素, 并把最大元素移到有序区来实现排序.
要了解这个排序方法,需要了解堆的数据结构,堆是一种完全二叉树结构,通常是通过一维数组来表现,它分为大根堆和小根堆,大根堆的子节点小于父节点.
堆排序过程:
- 由输入的原始数组构建大根堆,作为初始无序区
- 将堆顶元素和堆尾元素调换位置,堆顶元素进入有序区,无序区元素少一个
- 对无序区重新调整,建立新的大根堆
- 步骤2,3,直至堆的尺寸为1
参考网上图片如下:
以下通过三个函数构建堆排序:
def ajustHeap(L, low, high):
# 将处于low位置的元素调整下去(如果需要)
# high指的是堆的大小
# print('L before', L)
tmp = L[low]
i = low
j = 2*i
while j <= high:
if j <= high and j+1 <= high:
# j, j+1 为i的字节点, 此举在将j指向比较大的字节点
if L[j] < L[j+1]:
j+=1
if L[j] > tmp:
#如若字节点大于父节点, 则将字节点上移
L[i] = L[j]
# i指向tmp暂时的位置, j指向暂时位置的字节点
i = j
j = 2*i
else:
break
#发现tmp的位置
L[i] = tmp
# print('low', low)
# print('L after', L)
# print('===================')
def build_maxheap(L, Len):
# 用于构造初始的大根堆
for i in range(Len//2, 0, -1):
ajustHeap(L, i, Len)
return L
def heap_sort(L):
L.insert(0, 0)
# 序号从1开始,所以插入一个0
Len = len(L)-1
build_maxheap(L, Len)
for idx in range(Len, 1, -1):
L[1], L[idx] = L[idx], L[1] # 交换堆顶元素和最后一个元素
ajustHeap(L, 1, idx-1) # 重新调整堆, 将最大值移至堆顶
return L[1:]
L = [49,38,65,97,76,13,67,47]
heap_sort(L)
# [13, 38, 47, 49, 65, 67, 76, 97]
We can also implement heap sort with heapq package:
排序算法稳定性的问题
排序算法稳定性的定义:
若在原序列中ri > rj, 且ri在rj前面,在排序结束之后,ri和rj的相对次序仍未改变,则改算法稳定
具体细节解释见链接
总结来说,稳定的算法:冒泡,插入,归并。不稳定的为:选择,快速,希尔,堆排序