TOC
Introduction
在此总结传统机器学习算法,主要有:
一. 监督学习(Supervised Learning):
- 线性回归(Linear Regression)
- 逻辑回归(Logistic Regression Classifier)
- 最近紧邻法(K-nearest Neighbors)
- 决策树(Decision Tree)
- 随机森林(Random Forest)
- 支持向量机(Support Vector Machine)
- 朴素贝叶斯(Naive Bayes)
二. 非监督学习(Unsupervised Learning):
- K-平均聚类(k-means-clustering)
监督学习
监督学习:训练时用label data. 问题主要分为两类:
- 回归问题(Regression)
- 分类问题(Classification)
线性回归
Linear regression adopts a linear approch to model the relationship between dependent variable(target) and one or several independent variable (predictor)
线性回归为最简单的回归问题,运用线性预测模型来建模。
定义残差平方和RSS(Residual Sum of Square )如下: \(RSS = \sum_{i}(y_{true}-y_{predict})^2\) 计算方法为:Ordinary least square 直接求解; 梯度下降迭代求解。
算法:
- Given X, want $y_{predict}$,
- Param $w=R^{n}$, $b\in R$
- Output: $y_{predict}=w^Tt + b$
如下图:
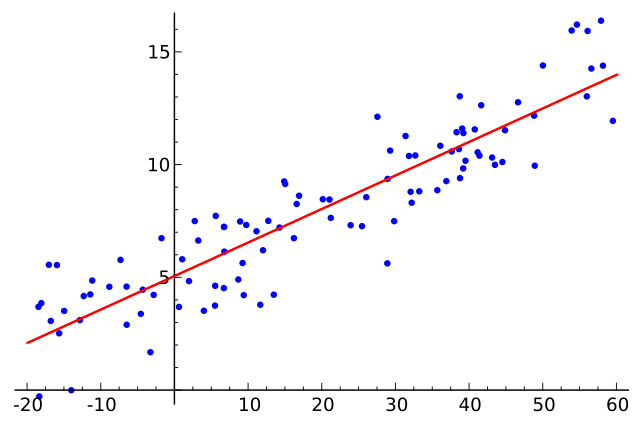
逻辑回归
One of classification algorithms, actually single layer neural network with sigmoid function as activation function
通常用于二元分类(Binary Classification),可理解为一层的神经网络系统。
算法:
- Given X, want $y_{predict}$,
- Param $w=R^n$, $b\in R$
- Output: $y_{predict} = \sigma(w^Tt +b)$ where $\sigma(z) = \frac{1}{1 + e^{-z}}$
Loss function(single sample):
- $L(y’, y)=-(ylog(y’) + (1-y)log(1-y’))$
Cost function(entir train set):
- $J(w, b) = \frac{1}{m}\sum_{i=1}^{n}L(y’^{(i)}, y^{(i)})$
计算方法:
- 梯度下降法
对于Multiclass classification 问题: one-over-many approach
最近紧邻法 (KNN)
Explain
- one of supervised learning both for classfication and regression, simplely remember all of training data(possible strored into a fast indexing structure such ball tree or KD tree)
- Process
- calculate the Euclidean distance between the query and all training data
- get K nearest neighbers
- for classification, vote for the most frequent labels; for regression, average the labels
- pros:
- easy, no need to build model; althoug simple, success in large number of problems such as handwritten digits and satellite image scenes
- cons:
- become slow when number of training data increase
Decision Tree
Decision tree works by successively splitting the dataset into small segments until the target variable are the same or until the dataset can no longer be split. Model behaves with “if this then that” conditions until yield the final result. It’s a greedy algorithm which make the best decision at the given time without concern for the global optimality. It can be used both for classfication and regression. In terms of classification, the majority of labels from the child nodes are selected as result; in case of regression, average of labels of the child nodes are selected as result
There are three steps in this method
- Selection of split feature
- classification criterion 3. infomation gain(entropy) 4. Gini coefficiency
- regression criterion 4. MAE 5. MSE
- Creation of decision trees
- Tree prune
- By minimize loss functions(cost function)
Pro and crons:
- Pros: easy to understand; no need to process data beforehead; no need to know the distribution of the data
- Cons: tend to overfit
Three type of algorithms
- ID3
- C4.5
- CART(classification and regression tree)
| Dimensions | ID3 | C4.5 | CART |
|---|---|---|---|
| Split Criterion | Information gain | Information gain ratio (Normalized information gain) | Gini |
| Types of Feature | Categorical feature | Categorical & numerical feature | Categorical & numerical features |
| Type of Problem | Classification | Classification | Classification & regression |
| Type of Tree | multiway tree | multiway tree | Binary tree |
Random Forest
- ensemble learning by combning serveral decision tree using bagging
- it reduces variance
- several decision trees are creating using sampling: every tree select subset of the datasets or subsets of all the features. Their results will be averaged as the final result.
主要有两种方法:
- Bagging (combining serveral decision tree)
- Sampling (subset of datasets or subset of features)
应用场景:数据维度相对较低,对准确度有较高要求
支持向量机 (Support Vector Machine)
- Supervised learning which is commonly use for classification.
- The goal is to find the the hyperplane that have the greatest margin between the hyperplane and the support vectors. This hyperplane will make sure all the data are correctly classified.
- If the hyperplane can’t be found in the feature space, then the features will be mapped into a higher dimensional space with kernel tricks.
- Concepts explain
- Margin: the distance between the hyperplane and the nearest data points (support vector).
- Support vector: the points that are close to the hyperplane, which, if removed, would alter the position of hyperplane. they are critical elements in the datasets
- Kernel tricks: It’s a method to map the data into higher dimensions so that we can classified them to different class with a hyperplane.
- Instead of getting the map function from low dimensions to high dimensions, kernel methods accepts the original vectors in lower dimensional space and return the product of the transformed vectors in the higher dimensions.
- The most used kernel are: polymomial function and radial basis function(RBF). Other kernels are linear kernel and sigmoid kernel.
- Pros: accuracy; works well on small cleaner dataset
- Cons: less effective on noisier data with overlapping classes; RF is more automated to train. However regarding SVM, there are more things to worry about such as the choose of kernel methods, the regularization penalty and so on.
- Usage: text classification
Ref 1, 2, 3
朴素贝叶斯(Naive Bayes Classifier)
- Supervised Learning algorithm for classification. A collection of algorithms that based on Bayes Theorem. And it’s solved with Maximum A Posterior estimation
- Naive: based on the “naive” assumption of conditional independence of every pairs of features given the value of the target variable
- which means that every feature contributes independently to the target variable
- Naive: based on the “naive” assumption of conditional independence of every pairs of features given the value of the target variable
- There different kinds of naive bayes classifier, they differ mainly by the assumptions they make regarding the distribution of $P(x_i/y)$
- Gaussian naive Bayes
- Multinormial naive Bayes
- Bernoulli naive Bayes
- cagegory naive Bayes
- Pros: relatively simple; easy to train; run fast
- Cons: In real case, features are not all independent
- Usage: document classification and text spam detection
Bayes Theorem
- \(P(A/B)P(B) = P(B/A)P(A)\) \(P(A/B) = \frac{P(B/A)P(A)}{P(B)}\)
Unsupervised Learning
K-means
Explain
- Unsupervised learning
- Process:
- Specify the desired number of clusters K
- Assign every observation randomly to 1 to K cluster
- Iterate until the cluster centroid stop changing
- Calculate the centroid of each cluster (centroid is the vector of the all features means for the observations in the kth cluster)
- assign each observation to the cluster whose centroid is closest (Euclidean Distance)
- Pros:
- Cons:
- likely end up in a local optimum, several runs with independent init might be necessary
Ref
- Support Vectors Machines - A simple explanation
- Introduction to Statistical Learning with Application in R
- 统计学习方法 - 李航
- Naive Bayes Classifier - Scikit-learn documents